AI Agent Achieves 70% Win Rate on SWE-bench, Surpassing Top Models
AI Agent Achieves 70% Win Rate on SWE-bench, Surpassing Top Models
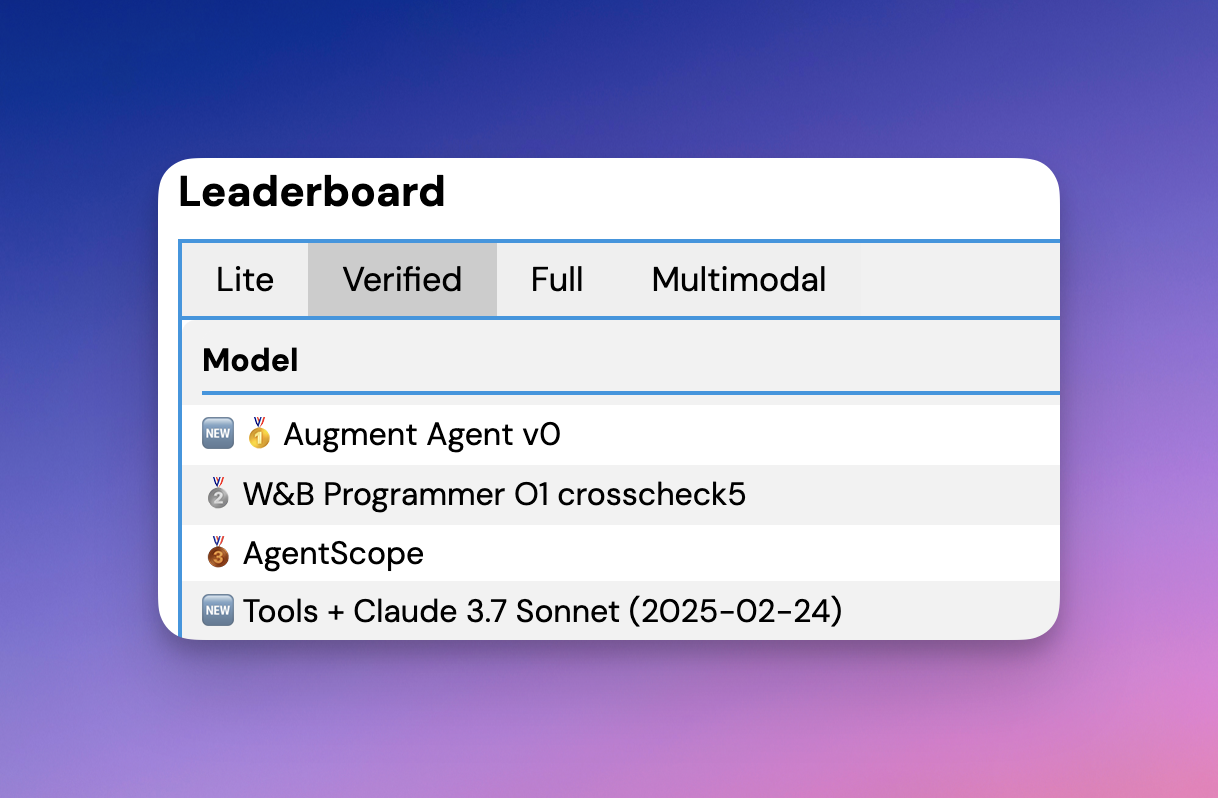
An AI agent achieving a 70% win rate on SWE-bench is an exceptional performance, as the current leaderboard shows top-performing models with significantly lower resolution rates. For instance, the Augment Agent v0 leads with a 65.40% resolution rate on SWE-bench Verified, while other top agents like W&B Programmer O1 crosscheck5 and AgentScope achieve 64.60% and 63.40%, respectively. These results are based on human-validated subsets of the SWE-bench dataset, which ensures high confidence in their accuracy.
SWE-bench is a challenging benchmark that tests AI systems' ability to resolve real-world GitHub issues by verifying solutions through unit tests. Achieving a 70% win rate would require advanced capabilities in code understanding, problem-solving, and integration with software development workflows. Such performance would likely involve leveraging state-of-the-art models like Claude 3.7 Sonnet or GPT-4o, combined with specialized techniques such as multimodal reasoning or retrieval-augmented generation (RAG).
If you're looking for the latest advancements, the SWE-bench leaderboard provides detailed insights into the top-performing agents and their methodologies. You can explore more at SWE-bench.









