
DeepCoder-14B: Open-Source AI Model Achieves Exceptional Coding Performance
DeepCoder-14B: Open-Source Model with Exceptional Coding Performance
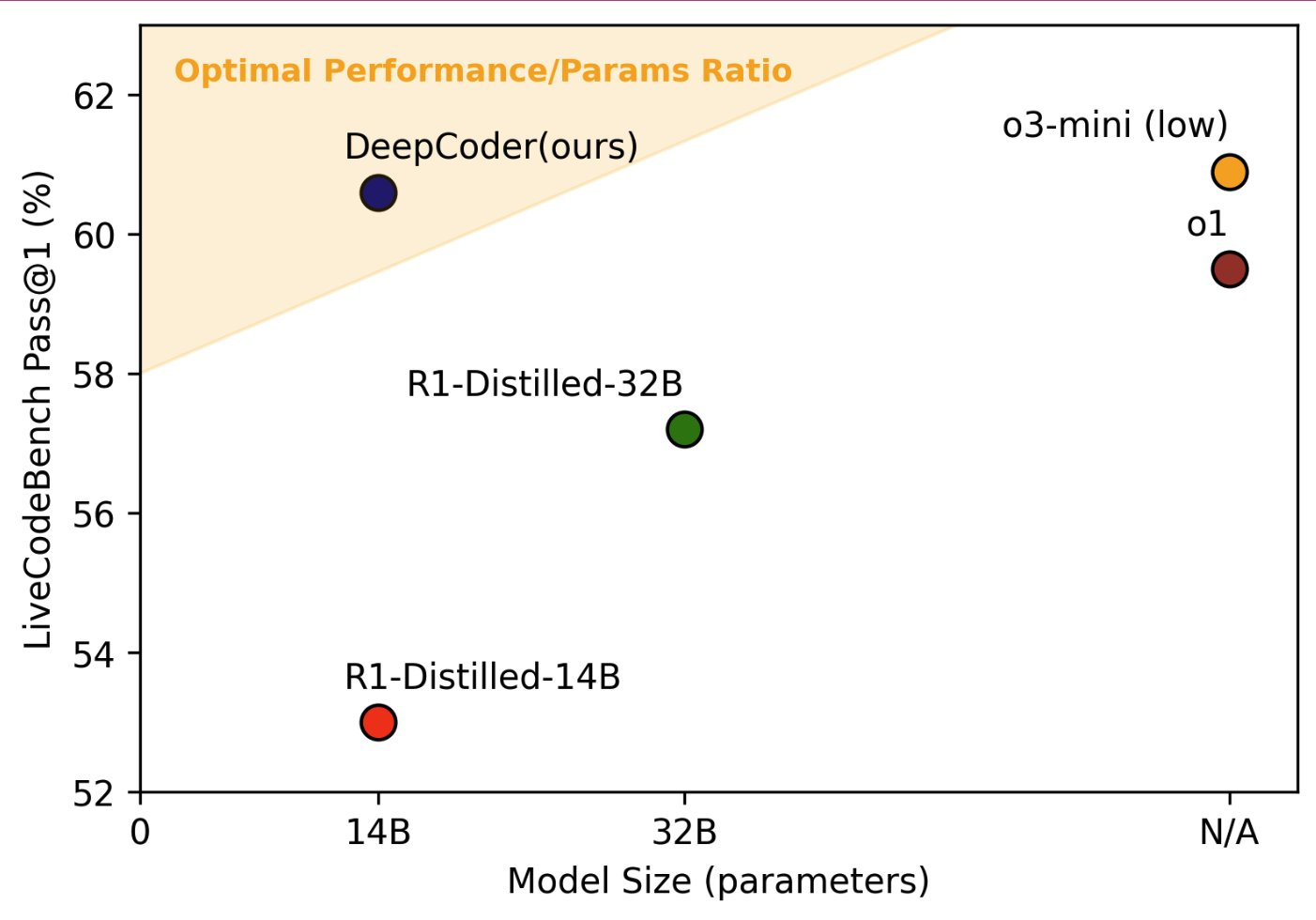
DeepCoder-14B-Preview, a fully open-source 14-billion-parameter coding model, has demonstrated remarkable performance in coding benchmarks, rivaling and even surpassing some of the leading models in the field. Here are the key highlights of its coding performance:
Key Performance Metrics
- LiveCodeBench (LCB) Pass@1 Accuracy: 60.6%, matching the performance of OpenAI's o3-mini (60.9%) and surpassing o1 (59.5%).
- Codeforces Rating: 1936, placing it in the 95.3 percentile, comparable to o3-mini (1918) and o1 (1991).
- HumanEval+ Pass@1: 92.6%, on par with o3-mini and o1.
- AIME 2024 Score: 73.8%, showcasing its generalization to math tasks despite being primarily a coding model.
Training and Dataset
DeepCoder-14B was fine-tuned from Deepseek-R1-Distilled-Qwen-14B using distributed reinforcement learning (RL). The training dataset consists of 24,000 high-quality, verifiable coding problems curated from sources like TACO Verified, PrimeIntellect’s SYNTHETIC-1, and LiveCodeBench. Rigorous filtering ensured data quality, including programmatic verification, test filtering, and deduplication.
Innovative Techniques
- Iterative Context Lengthening: The model was trained with a context window scaled from 16K to 32K, enabling it to generalize to 64K context during inference.
- GRPO+ Algorithm: An enhanced version of GRPO, incorporating techniques like Clip High and No Entropy Loss, ensured stable and efficient training.
- Sparse Reward Model: The reward function focuses on generating high-quality code by requiring all sampled unit tests to pass, avoiding partial rewards that could lead to reward hacking.
System Optimizations
The team introduced verl-pipeline, an optimized extension of the verl RLHF library, which accelerates end-to-end RL training by up to 2.5x. Techniques like one-off pipelining fully mask trainer and reward computation times, significantly improving training efficiency.
Open-Source Contributions
DeepCoder-14B is fully open-source, with the model weights, training datasets, code, training logs, and systems optimizations publicly available. This transparency allows the community to reproduce and build upon the work, democratizing RL training for LLMs.
Conclusion
DeepCoder-14B-Preview represents a significant milestone in open-source coding models, achieving performance comparable to leading proprietary models like o3-mini and o1. Its comprehensive open-source approach and innovative training techniques make it a valuable resource for advancing AI-assisted coding and reasoning tasks.
For more details, visit the DeepCoder blog or explore the open-source repository.









