Running Large Language Models Locally with Docker
Running LLMs Locally with Docker
Running large language models (LLMs) locally using Docker has become more accessible with tools like Docker Model Runner and AnythingLLM. These tools simplify the process of setting up, managing, and experimenting with LLMs on your local machine.
Docker Model Runner
Docker Model Runner, introduced in Docker Desktop 4.40 for macOS on Apple silicon, allows developers to easily pull, run, and test LLMs locally. It provides:
- Local LLM inference powered by an integrated engine built on top of llama.cpp.
- GPU acceleration on Apple silicon.
- A collection of popular, usage-ready models packaged as standard OCI artifacts.
To enable Docker Model Runner, use the command: docker desktop enable model-runner. You can also specify a TCP port for host process interaction.
For example, to pull and run a model like SmolLM, use:
docker model pull ai/smollm2:360M-Q4_K_M
docker model run ai/smollm2:360M-Q4_K_M "Give me a fact about whales."Model Runner exposes an OpenAI-compatible API, making it easy to integrate with existing applications.
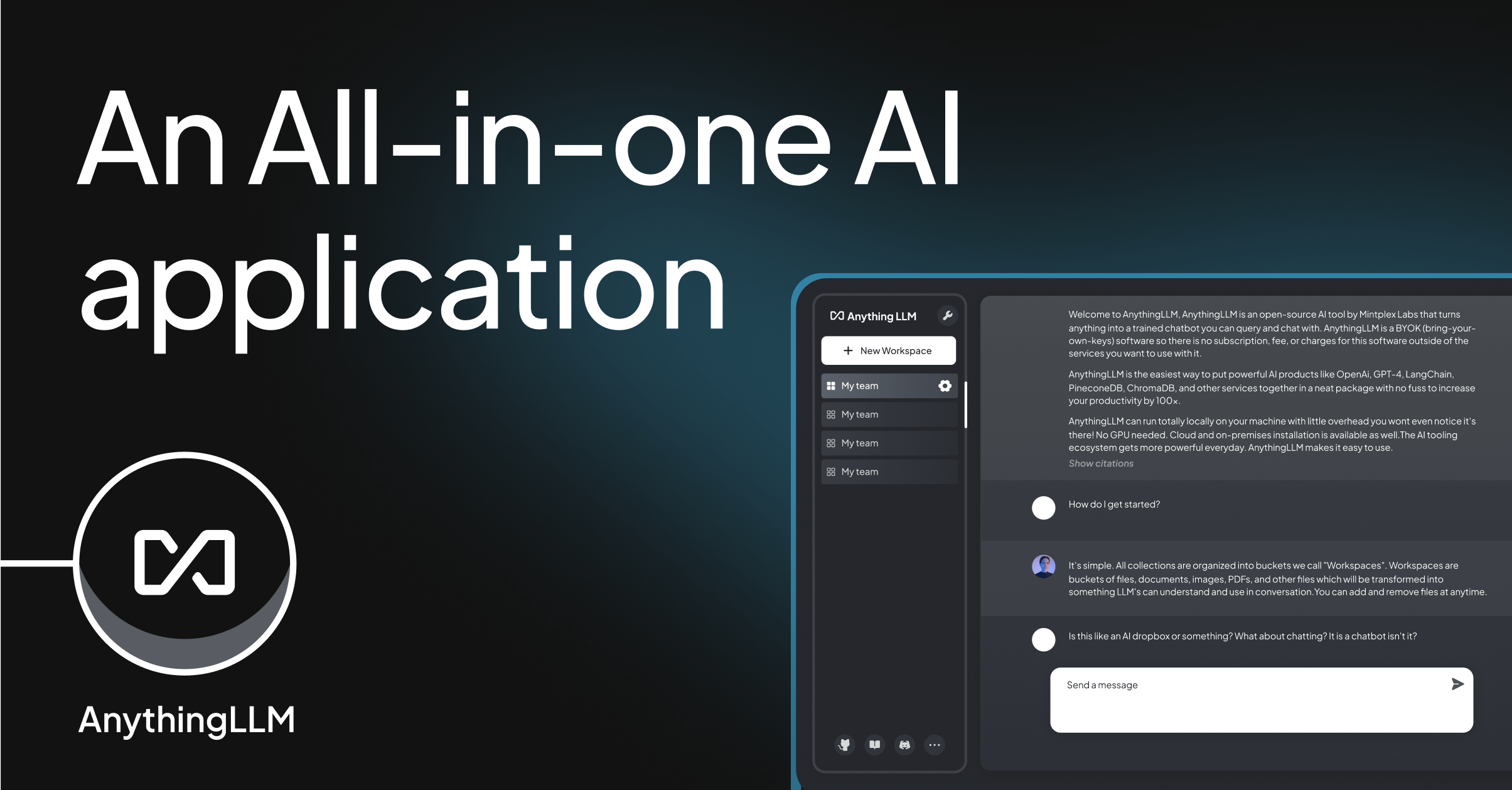
AnythingLLM
AnythingLLM is an all-in-one AI application that supports both desktop and Docker installations. It offers:
- Built-in RAG (Retrieval-Augmented Generation) and AI agents.
- Multi-user support and permissions.
- Compatibility with various LLMs, vector databases, and embedding models.
AnythingLLM allows you to chat with your documents, create custom AI agents, and manage workspaces efficiently. It supports a wide range of LLMs, including OpenAI, Azure OpenAI, and open-source models like llama.cpp.
For Docker installation, refer to the AnythingLLM Docker documentation.
Conclusion
Both Docker Model Runner and AnythingLLM provide powerful solutions for running LLMs locally. Whether you're looking for a quickstart with Docker Model Runner or a comprehensive AI application with AnythingLLM, these tools make it easier to integrate AI into your local development workflow.









