LLMs and OCR: Challenges and Complementary Strengths in Data Extraction
LLMs and OCR: Challenges and Complementary Strengths in Data Extraction
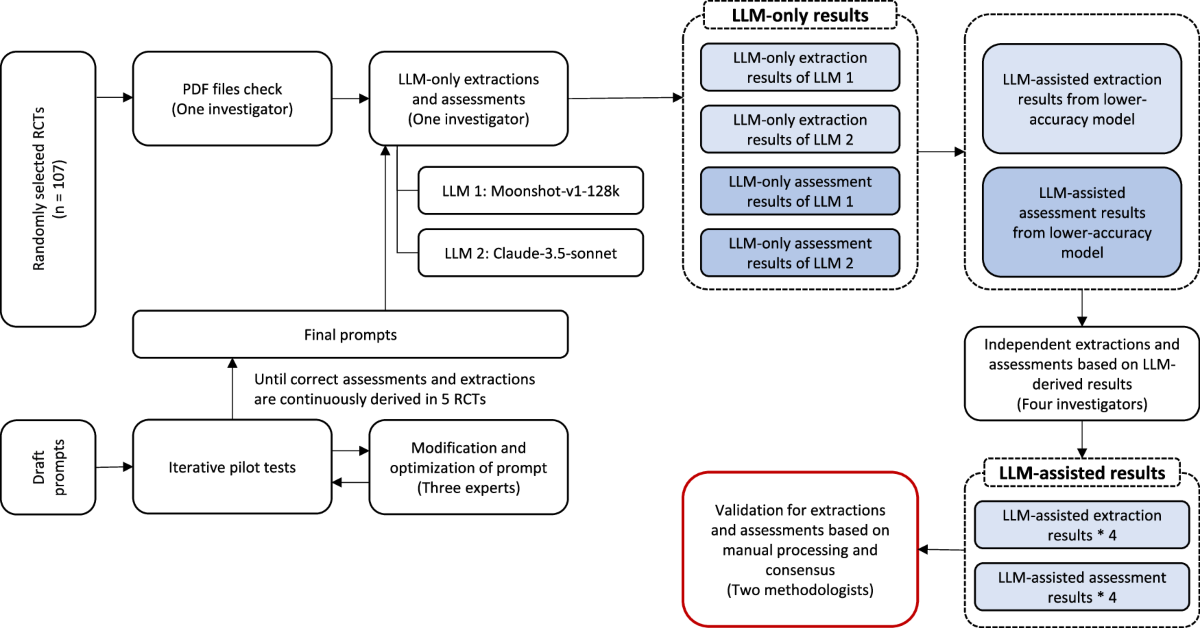
Language models (LLMs) have shown remarkable capabilities in various natural language processing tasks, including data extraction from text. However, when it comes to Optical Character Recognition (OCR) and data extraction from scanned documents, LLMs face several limitations:
1. Image Quality and Noise
LLMs are primarily text-based and may struggle with poor image quality, such as low resolution, blurriness, and noise. These issues can lead to inaccurate or incomplete text extraction. Traditional OCR systems are better equipped to handle such image-related challenges.
2. Layout and Structure
Documents often have complex layouts with tables, columns, and various formatting. LLMs may not always correctly interpret the structure of the document, leading to errors in data extraction. Advanced OCR systems can better understand and preserve the layout and structure of the document.
3. Domain-Specific Terms and Abbreviations
LLMs may not be well-versed in domain-specific terminology or abbreviations, which can be crucial for accurate data extraction. Specialized OCR systems can be trained to recognize and handle such terms more effectively.
4. Handwriting Recognition
Handwritten text presents a significant challenge for LLMs. While some advanced LLMs can handle handwriting to some extent, they are generally less effective compared to specialized OCR systems designed for handwriting recognition.
5. Language and Script Support
LLMs may have limitations in supporting a wide range of languages and scripts, especially less common ones. Traditional OCR systems can be configured to handle a broader variety of languages and scripts, ensuring more accurate data extraction.
6. Integration and Automation
Integrating LLMs into existing document processing workflows can be complex and may require significant customization. Traditional OCR systems often come with robust integration and automation capabilities, making them easier to implement in business processes.
Despite these limitations, there are ongoing efforts to combine the strengths of LLMs and traditional OCR systems to create more advanced and accurate data extraction solutions. For example, using LLMs to refine and validate the output of OCR systems can enhance overall performance.









