3FS
by DeepSeekWhat is 3FS?
3FS (Fire-Flyer File System) is a high-performance distributed file system developed by DeepSeek, specifically designed for AI training and inference tasks. By leveraging modern SSD and RDMA network technologies, 3FS aggregates the throughput of thousands of SSDs and the network bandwidth of hundreds of storage nodes, delivering up to 6.6 TiB/s read throughput. It ensures strong consistency and provides a universal file interface, eliminating the need to learn new storage APIs. 3FS excels in large-scale data processing and inference optimization, achieving a throughput of 3.66 TiB/min in the GraySort test and a KVCache read throughput of up to 40 GiB/s.
Key Features of 3FS
- High-Performance Data Access: Aggregates the throughput of thousands of SSDs and the network bandwidth of hundreds of storage nodes, delivering up to 6.6 TiB/s read throughput. Supports high-throughput parallel read/write in large-scale clusters, optimizing data loading efficiency for AI training and inference tasks.
- Strong Consistency Guarantee: Implements Chain Replication with Apportioned Queries (CRAQ) technology to ensure strong data consistency, simplifying application development complexity.
- Universal File Interface: Provides stateless metadata services, supporting transactional key-value storage (e.g., FoundationDB), eliminating the need for users to learn new storage APIs.
- Optimized AI Workloads:
- Data Preparation: Efficiently manages large amounts of intermediate output, supporting hierarchical directory structures.
- Data Loading: Supports random access across compute nodes without the need for prefetching or dataset shuffling.
- Checkpoint Support: Provides high-throughput parallel checkpointing for large-scale training.
- KVCache: Offers a high-throughput, large-capacity cache alternative for inference tasks, optimizing inference efficiency.
- High Scalability and Flexibility: Supports large-scale cluster deployment, suitable for diverse application scenarios from single-node to thousands of nodes.
Technical Principles of 3FS
- Disaggregated Architecture: Based on a compute-storage separation design, it centralizes storage resources and uses high-speed networks (e.g., RDMA) for efficient data transfer, allowing applications to access storage resources in a "location-independent" manner, simplifying resource management.
- Chain Replication with Apportioned Queries (CRAQ): To achieve strong consistency, 3FS is based on CRAQ technology. It ensures data consistency across multiple replicas through chain replication and optimizes read performance with apportioned queries, reducing latency.
- Stateless Metadata Service: 3FS introduces a stateless metadata service based on transactional key-value storage (e.g., FoundationDB), enhancing system scalability and reducing metadata management complexity.
- Direct I/O and RDMA Optimization: Uses Direct I/O to directly access SSDs, avoiding file caching to reduce CPU and memory overhead, and employs RDMA technology for efficient data transfer, further enhancing performance.
- KVCache Technology: In inference tasks, it caches critical intermediate results using KVCache to avoid redundant calculations, significantly improving inference efficiency. KVCache combines high throughput and large capacity, serving as a low-cost alternative to DRAM cache.
- Data Locality Optimization: Optimizes data layout and access patterns to reduce data transfer latency and bandwidth consumption, particularly excelling in large-scale distributed training and inference tasks.
Performance of 3FS
- Large-Scale Read Throughput: In a cluster of 180 storage nodes, each equipped with 2×200Gbps InfiniBand NICs and 16×14TiB NVMe SSDs, approximately 500+ client nodes were used for read stress testing, each configured with 1x200Gbps InfiniBand NIC. Under background traffic from training jobs, the final aggregate read throughput reached approximately 6.6 TiB/s.
- GraySort Performance Test: 3FS performed exceptionally well in the GraySort benchmark, a large-scale data sorting test used to measure the data processing capability of distributed systems. The test cluster included 25 storage nodes (each with 2 NUMA domains, 1 storage service per domain, 2×400Gbps NIC) and 50 compute nodes (each with 192 physical cores, 2.2 TiB memory, 1×200Gbps NIC). In this test, 3FS successfully completed the sorting of 110.5 TiB of data distributed across 8192 partitions in just 30 minutes and 14 seconds, achieving an average throughput of 3.66 TiB/min.
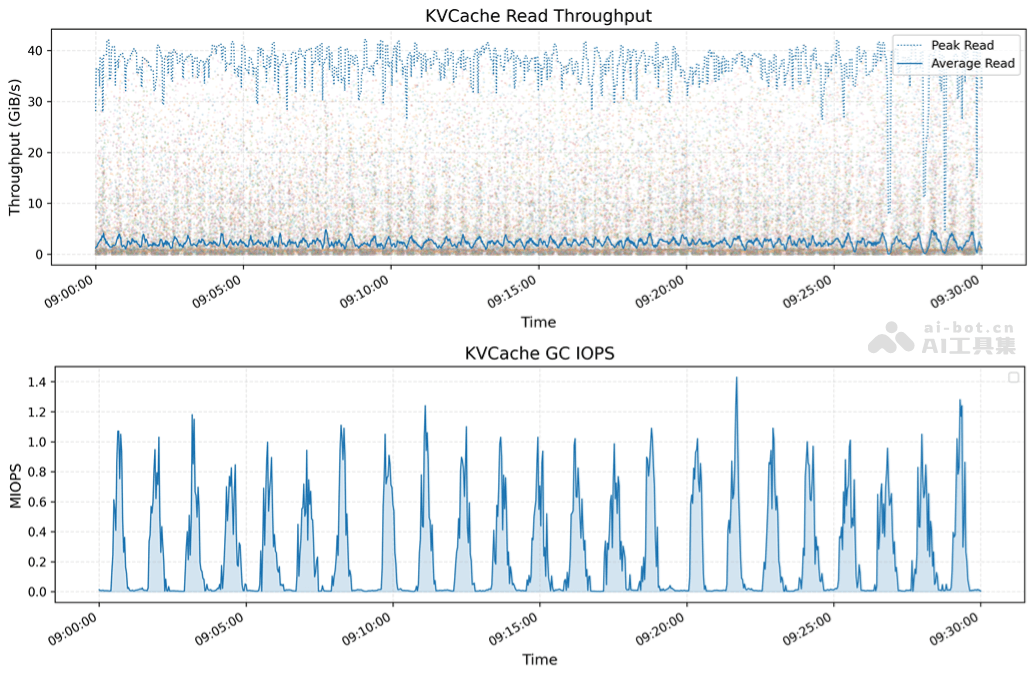
- KVCache Inference Optimization: KVCache is a caching technology designed by 3FS to optimize LLM (Large Language Model) inference processes by caching key vectors and value vectors in the decoding layer to avoid redundant calculations. In KVCache performance tests, the peak read throughput reached 40 GiB/s, significantly improving inference efficiency. KVCache's garbage collection (GC) operations also demonstrated high IOPS performance, ensuring efficient cache management and updates.
Project Address of 3FS
- GitHub Repository: https://github.com/deepseek-ai/3FS
Application Scenarios of 3FS
- Large-Scale AI Training: Efficiently supports rapid read/write of massive data, enhancing training speed.
- Distributed Data Processing: Optimizes data loading and management, supporting random access without the need for prefetching or shuffling.
- Inference Optimization: Reduces redundant calculations by caching intermediate results with KVCache, improving inference efficiency.
- Checkpoint Support: Provides high-throughput parallel checkpointing, ensuring the stability and recoverability of training tasks.
- Multi-Node Computing Environment: Seamlessly integrates into large-scale clusters, supporting flexible scaling to meet the needs of various AI applications.
Framework Features
Getting Started
Screenshots & Images

Stats
Community & Support
Similar Frameworks
Helping everyone find the best AI for their work and daily life through deep analysis and honest comparisons.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









