AniPortrait
by TencentWhat is AniPortrait?
AniPortrait is an open-source framework developed by Tencent that generates photorealistic, lip-synced animations from audio and a reference portrait image. It is designed to produce high-quality, temporally consistent videos with natural facial expressions and precise lip movements.
Key Features
- Audio-Driven Animation: Automatically generates facial animations synchronized with input audio, including lip movements, expressions, and head poses.
- High-Quality Visuals: Uses a diffusion model and motion module to produce realistic, high-resolution animations.
- Temporal Consistency: Ensures smooth and natural character movements over time.
- Flexibility: Allows editing and customization of animations using 3D facial representations.
- Precise Facial Expressions: Captures subtle lip movements and complex facial expressions accurately.
- Reference Image Consistency: Matches the generated animations visually with the original portrait.
How It Works
AniPortrait consists of two main modules:
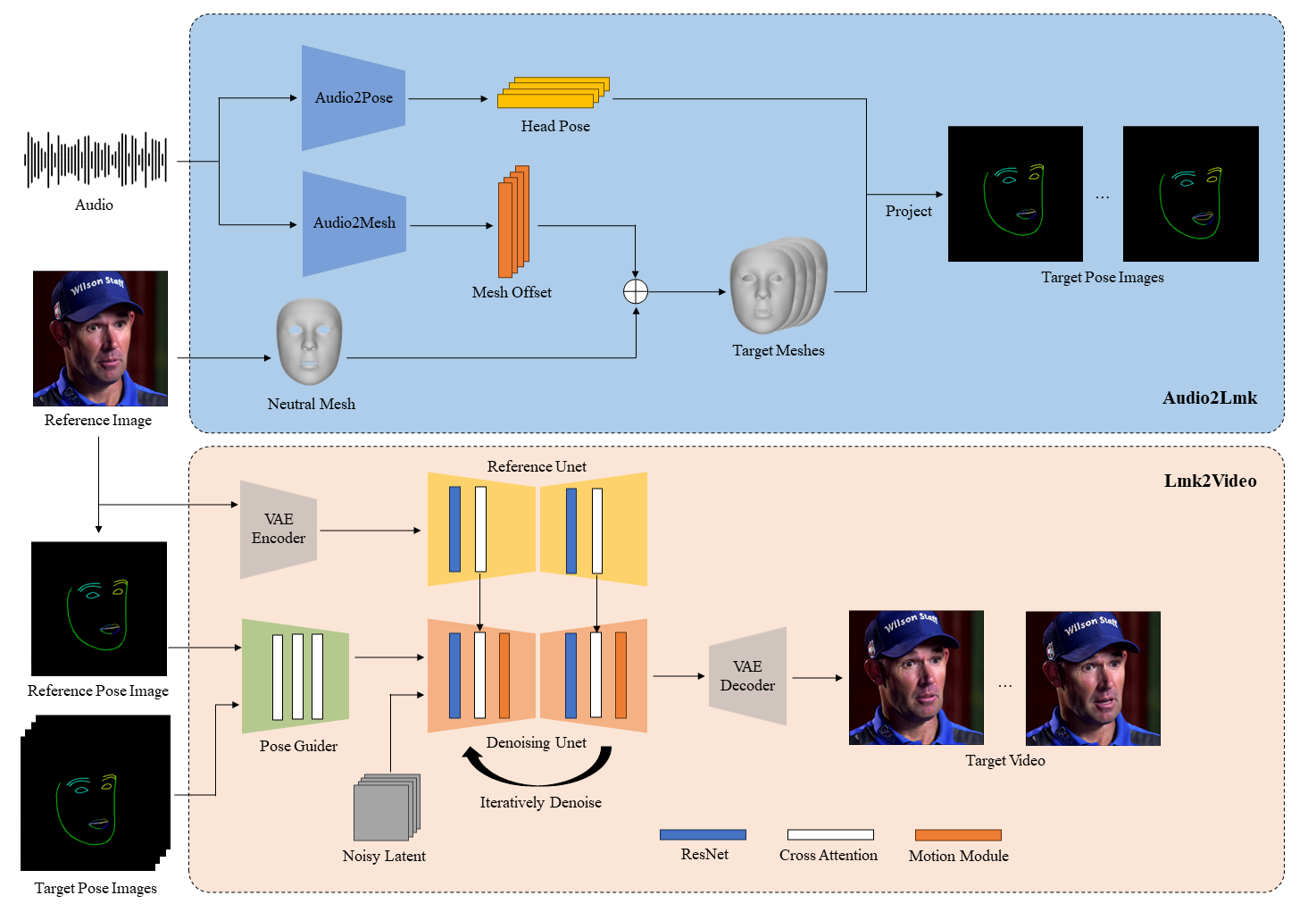
1. Audio2Lmk Module
This module extracts 3D facial meshes and head pose information from audio input. It uses a pre-trained wav2vec model to identify pronunciation and intonation, which are crucial for generating realistic animations. These features are then transformed into 3D meshes and converted into 2D facial landmarks.
2. Lmk2Video Module
This module generates temporally consistent videos from the reference portrait and facial landmarks. It uses Stable Diffusion 1.5 as the backbone, combined with a temporal motion module, to produce high-quality video frames. A ReferenceNet ensures consistent facial identity throughout the animation.
Official Links
- GitHub Repository: https://github.com/Zejun-Yang/AniPortrait
- arXiv Research Paper: https://arxiv.org/abs/2403.17694
- Hugging Face Model: https://huggingface.co/ZJYang/AniPortrait/tree/main
- Hugging Face Demo: https://huggingface.co/spaces/ZJYang/AniPortrait_official
Getting Started
To get started with AniPortrait, clone the GitHub repository and follow the setup instructions. The repository includes detailed documentation, examples, and pre-trained models to help you generate your own animations.
Framework Features
Getting Started
Screenshots & Images




Stats
Community & Support
Similar Frameworks
Helping everyone find the best AI for their work and daily life through deep analysis and honest comparisons.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









