
Diffutoon
by Alibaba, East China Normal University (ECNU)Diffutoon is an AI framework developed by Alibaba and ECNU researchers that converts realistic videos into cartoon anime styles using diffusion models.
What is Diffutoon?
Diffutoon is an AI framework developed by researchers from Alibaba and East China Normal University (ECNU) that transforms realistic videos into cartoon anime styles. It utilizes diffusion model-based editable cartoon coloring technology to achieve high-resolution and long-duration rendering of videos. Diffutoon also features content editing capabilities, allowing users to adjust video details based on text prompts, ensuring high visual quality and consistency in the final output.
Features of Diffutoon
- Cartoon Video Rendering: Diffutoon uses diffusion models to convert realistic videos into cartoon or anime styles, achieving a flat and stylized visual effect. The transformation includes changes in color and texture, as well as artistic processing of elements like lighting and contours to mimic hand-drawn animation.
- High-Resolution Support: Diffutoon can handle high-resolution videos, supporting at least 1536×1536 pixels, ensuring clarity and detail even on large or high-definition displays, making it suitable for high-quality video production and presentation.
- Video Editing: Users can edit video content based on text prompts. Diffutoon can recognize and adjust specific parts of the video according to these prompts. The editing function supports modifications to the appearance and attributes of characters and scene elements, such as changing clothing colors or adjusting character expressions.
- Frame Consistency: Through specific algorithms and techniques, Diffutoon ensures that each frame in the video sequence maintains consistency in style and content, avoiding issues like flickering, sudden color changes, or incoherent content during playback, thereby improving the viewing experience.
- Structure Preservation: During the video stylization process, Diffutoon can identify and retain key structural information in the video, such as character outlines and object edges, ensuring that the main content and shapes remain clear and recognizable even after stylization.
- Automatic Coloring: Diffutoon features automatic coloring, selecting appropriate colors based on video content and style requirements. This not only improves production efficiency but also ensures color coordination and visual appeal, making the final video more harmonious in color.
Official Links for Diffutoon
- Official Project Page: https://ecnu-cilab.github.io/DiffutoonProjectPage/
- GitHub Repository: https://github.com/modelscope/DiffSynth-Studio
- arXiv Technical Paper: https://arxiv.org/abs/2401.16224
Technical Principles of Diffutoon
- Application of Diffusion Models: Diffutoon uses diffusion models as the core technology for image synthesis, learning the distribution characteristics of images and videos from datasets to achieve conversion from high-dimensional latent space to image data.
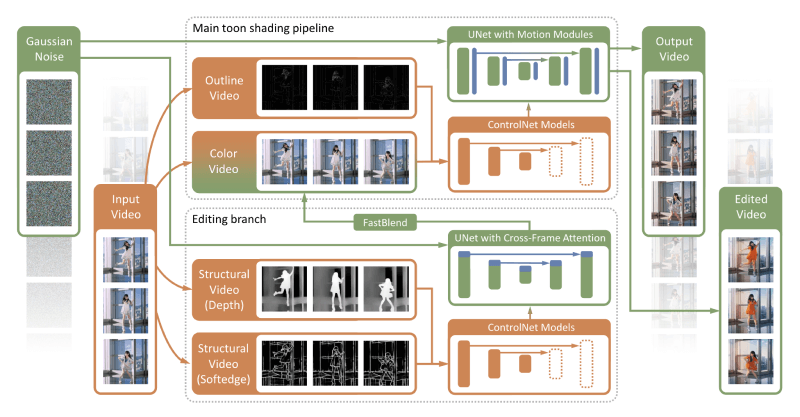
- Multi-Module Denoising: Diffutoon constructs a multi-module denoising model that combines technologies like ControlNet and AnimateDiff to address controllability and consistency issues in videos.
- Stylization, Consistency Enhancement, Structure Guidance, and Coloring: Diffutoon decomposes the cartoon coloring problem into four sub-problems, each solved by specific models:
- Stylization: Uses a personalized Stable Diffusion model for anime stylization.
- Consistency Enhancement: Inserts motion modules based on AnimateDiff into UNet to maintain content consistency between video frames.
- Structure Guidance: Uses the ControlNet model to extract and retain structural information in the video, such as contours.
- Coloring: Another ControlNet model is used for coloring, improving video quality even with low-resolution input.
- Sliding Window Method: Employs a sliding window method to iteratively update the latent embedding of each frame, helping to handle long videos and maintain frame coherence.
- Editing Branch: In addition to the main cartoon coloring pipeline, Diffutoon includes an editing branch that generates editing signals based on text prompts, provided to the main pipeline as colored videos.
- Efficient Attention Mechanism: Introduces Flash Attention to reduce GPU memory usage and improve the efficiency of processing high-resolution videos.
- Classifier-Free Guidance: Uses a classifier-free guidance mechanism to optimize visual quality based on text prompts.
- DDIM Scheduler: Uses the DDIM (Denoising Diffusion Implicit Models) scheduler to control the video generation process, balancing generation quality and speed.
- Post-Processing Methods: Employs post-processing techniques like FastBlend to further enhance long-term consistency and visual effects in videos.
Framework Features
Supported Tasks
Video Stylization
Content Editing
High-Resolution Video Rendering
Frame Consistency
Automatic Coloring
Tags
AI Video Editing
Cartoon Animation
Diffusion Models
High-Resolution Video
Video Stylization
Content Editing
Frame Consistency
Automatic Coloring
Structure Preservation
Video Processing
Getting Started
Screenshots & Images
Primary Screenshot

Additional Images

Stats
0
Views
0
Favorites
8157
GitHub Stars
Community & Support
Similar Frameworks
Helping everyone find the best AI for their work and daily life through deep analysis and honest comparisons.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.
© 2026 BestAI. All rights reserved.









