
Hyper-SD
by ByteDanceWhat is Hyper-SD?
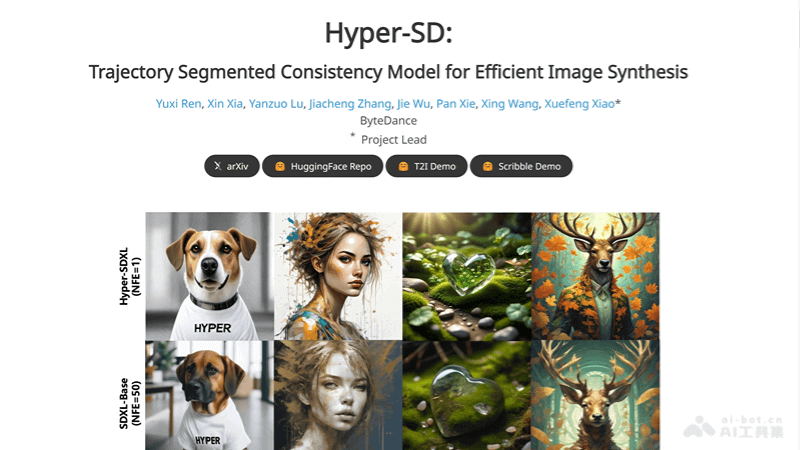
Hyper-SD is an efficient image synthesis framework developed by ByteDance researchers, designed to address the high computational costs of existing diffusion models during multi-step inference. By employing Trajectory Segmentation Consistency Distillation (TSCD) technology, it maintains data consistency across different time periods, effectively preserving the original ODE (Ordinary Differential Equation) trajectory. Additionally, it incorporates human feedback learning to optimize model performance in low-step inference scenarios and uses score distillation to further enhance single-step inference image quality. This framework significantly reduces the necessary inference steps while maintaining high image quality, enabling rapid generation of high-resolution images and advancing the field of generative AI.
Official Website and Resources
- Official Project Homepage: https://hyper-sd.github.io/
- Hugging Face Model: https://huggingface.co/ByteDance/Hyper-SD
- arXiv Research Paper: https://arxiv.org/abs/2404.13686
- Hyper-SD T2I Demo: https://huggingface.co/spaces/ByteDance/Hyper-SDXL-1Step-T2I
- Hyper-SD Scribble Demo: https://huggingface.co/spaces/ByteDance/Hyper-SD15-Scribble
How Hyper-SD Works
-
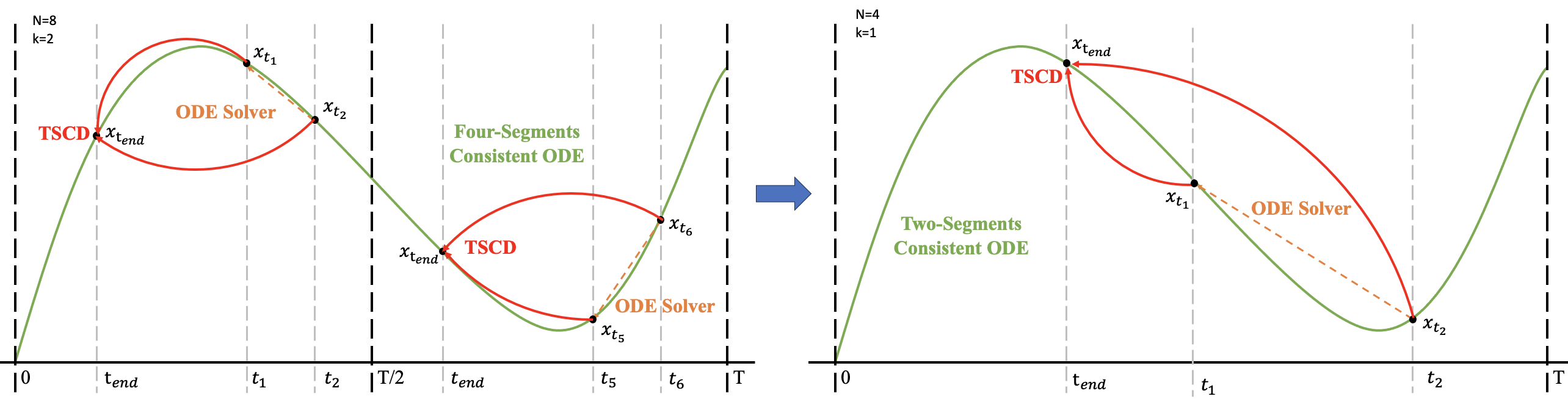
Trajectory Segmentation Consistency Distillation (TSCD): Divides the training time step range [0, T] into k uniform time periods. Performs consistency distillation within each time period, using the original model as the teacher and the student model gradually learning the teacher model's behavior. By progressively reducing the number of time periods (e.g., 8 → 4 → 2 → 1), the student model is trained to approximate the global behavior of the teacher model.
-
Human Feedback Learning (ReFL): Utilizes human feedback on image preferences to optimize the model. Trains a reward model to recognize and reward images that align more closely with human aesthetics. Through iterative denoising and direct prediction, combined with feedback from the reward model, the student model is fine-tuned.
-
Score Distillation: Uses the score functions of real and fake distributions to guide the single-step inference process. By minimizing the KL divergence between the two distributions, the student model's single-step generation performance is optimized.
-
Low-Rank Adaptation (LoRA): Employs LoRA technology to adapt and train the student model, making it a lightweight plugin that can be quickly deployed and used.
-
Training and Loss Function Optimization: Defines a loss function that combines consistency loss, human feedback loss, and score distillation loss. Uses optimization algorithms like gradient descent to train the student model while updating the LoRA plugin.
-
Inference and Image Generation: After training, the student model is used for the image generation inference process. Depending on the application scenario, an appropriate number of inference steps is selected to balance generation quality and efficiency.
-
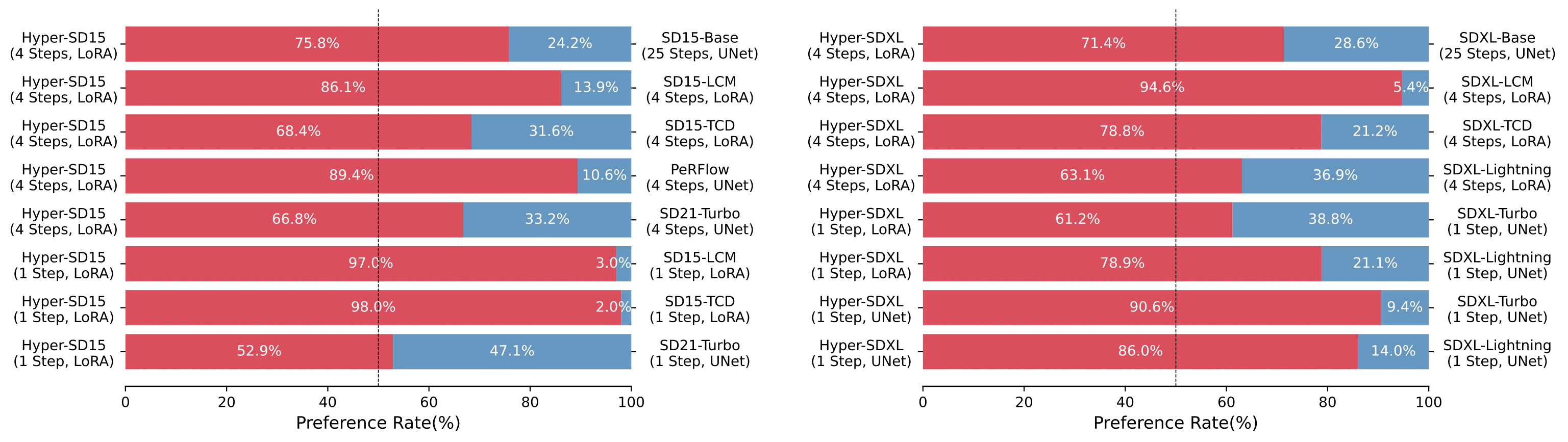
Performance Evaluation: Uses quantitative metrics (e.g., CLIP score, aesthetic score) and qualitative metrics (e.g., user studies) to evaluate the quality of generated images. Based on the evaluation results, model parameters are further adjusted and optimized.
Framework Features
Getting Started
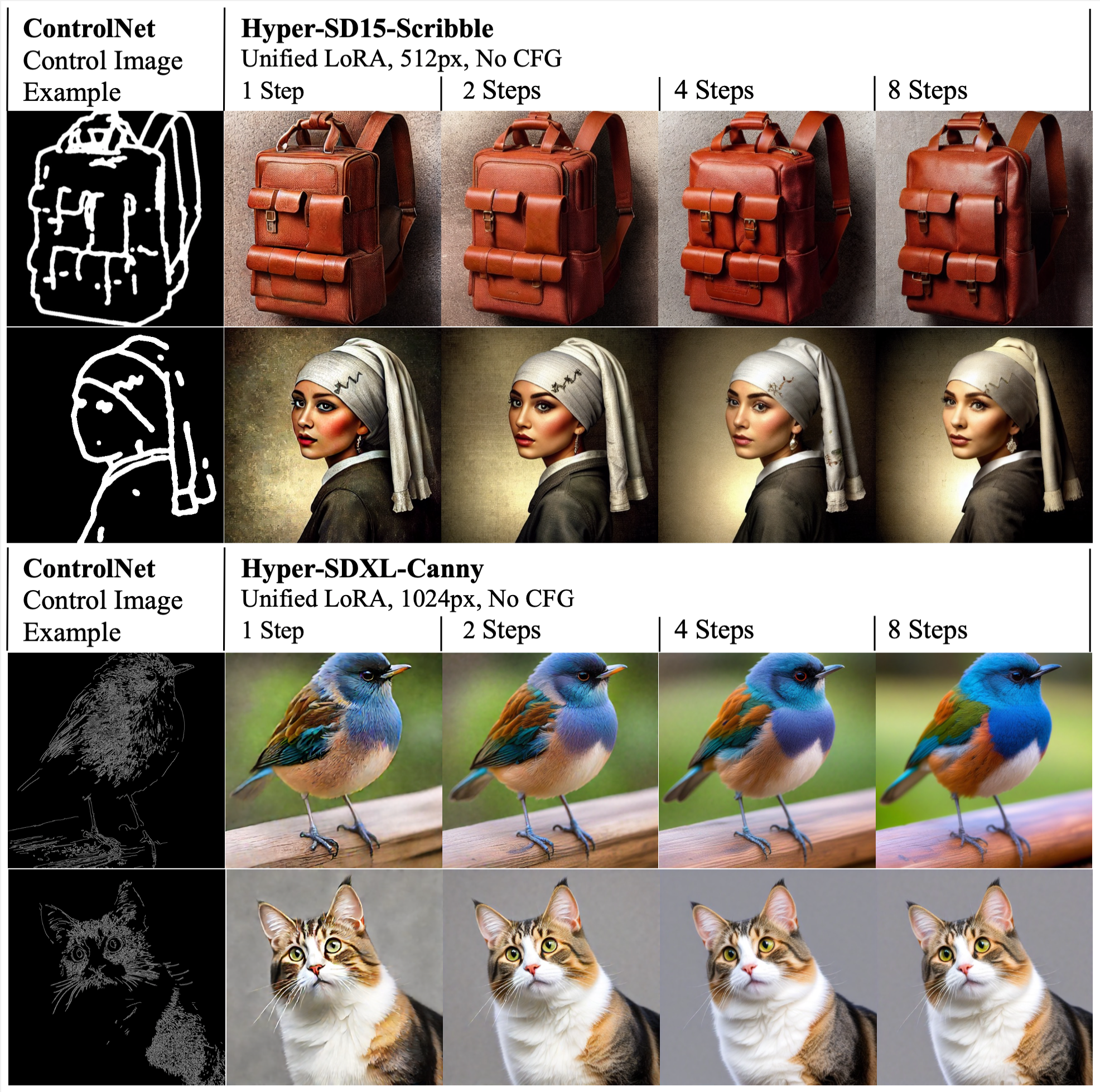
Screenshots & Images

Stats
Similar Frameworks
Helping everyone find the best AI for their work and daily life through deep analysis and honest comparisons.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









