
OLMo
by Allen Institute for Artificial Intelligence (AI2)What is OLMo?
OLMo (Open Language Model) is a fully open-source large language model (LLM) framework developed by Allen AI (AI2, Allen Institute for Artificial Intelligence). It is designed to promote collaborative research in the science of language models by providing a range of resources, including data, training code, model weights, and evaluation tools, enabling researchers to better understand and improve language models.

Key Features of OLMo
- Large-scale Pre-training Data: Based on AI2's Dolma dataset, which contains 3 trillion tokens, providing rich language learning materials.
- Diverse Model Variants: The OLMo framework includes four different model variants, each trained on at least 2 trillion tokens, offering researchers multiple options to suit different research needs.
- Detailed Training and Evaluation Resources: In addition to model weights, OLMo provides complete training logs, training metrics, and over 500 checkpoints, helping researchers better understand the training process and performance.
- Openness and Transparency: All code, weights, and intermediate checkpoints are released under the Apache 2.0 license, allowing researchers to freely use, modify, and distribute these resources to promote knowledge sharing and innovation.
Performance of OLMo Models
According to the OLMo paper, the OLMo-7B model was compared with several other models in zero-shot evaluations, including Falcon-7B, LLaMA-7B, MPT-7B, Pythia-6.9B, RPJ-INCITE-7B, and LLaMA-7B.
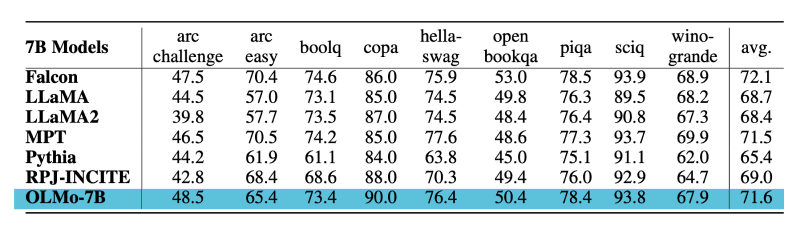
Here are the comparative results of OLMo-7B on some core tasks:
- Downstream Task Evaluation: In zero-shot evaluations on 9 core tasks, OLMo-7B performed best on 2 tasks (scientific questions and causal reasoning) and remained in the top three on 8 tasks, indicating strong competitiveness.
- Perplexity-based Evaluation: In the Paloma evaluation framework, OLMo-7B showed competitive performance in terms of perplexity (bits per byte) across multiple data sources, particularly outperforming other models on code-related data sources (e.g., Dolma 100 Programming Languages).
- Additional Task Evaluation: On 6 additional tasks (headqa en, logiqa, mrpcw, qnli, wic, wnli), OLMo-7B also performed better than or close to other models in zero-shot evaluations.
Framework Features
Getting Started
Screenshots & Images
Stats
Community & Support
Similar Frameworks
Recently Viewed
Helping everyone find the best AI for their work and daily life through deep analysis and honest comparisons.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









