OmniHuman
by ByteDanceWhat is OmniHuman?
OmniHuman is an end-to-end multimodal human video generation framework developed by ByteDance. It can generate realistic human videos based on a single human image and motion signals such as audio, video, or a combination of both. OmniHuman uses a multimodal motion condition hybrid training strategy to overcome performance bottlenecks caused by the scarcity of high-quality data. It supports images of any aspect ratio, including portraits, half-body, and full-body images, and can adapt to various scenarios. OmniHuman excels in singing, conversation, and gesture handling, supporting multiple visual and audio styles while being compatible with audio, video, and combined driving to generate high-quality video content.
Key Features of OmniHuman
- Multimodal-driven Video Generation:
- Supports audio-driven (e.g., speaking, singing) and pose-driven (e.g., gestures, movements) video generation, and can combine both for hybrid-driven natural human motion videos.
- Supports various input forms, including facial close-ups, half-body, and full-body images, compatible with different aspect ratios and styles.
- High Realism and Diverse Motions:
- The generated videos are visually highly realistic, featuring natural facial expressions, body movements, and smooth dynamic effects.
- Capable of handling complex actions and object interactions, such as playing instruments while singing or natural interactions between gestures and objects.
- Flexible Video Generation:
- Supports video generation of any aspect ratio and duration, generating video clips of varying lengths based on input signals.
- Compatible with various image styles, including realistic, cartoon, and stylized characters.
- Multi-scene Adaptability: Generates high-quality videos in various scenarios, including different backgrounds, lighting conditions, and camera angles.
Technical Principles of OmniHuman
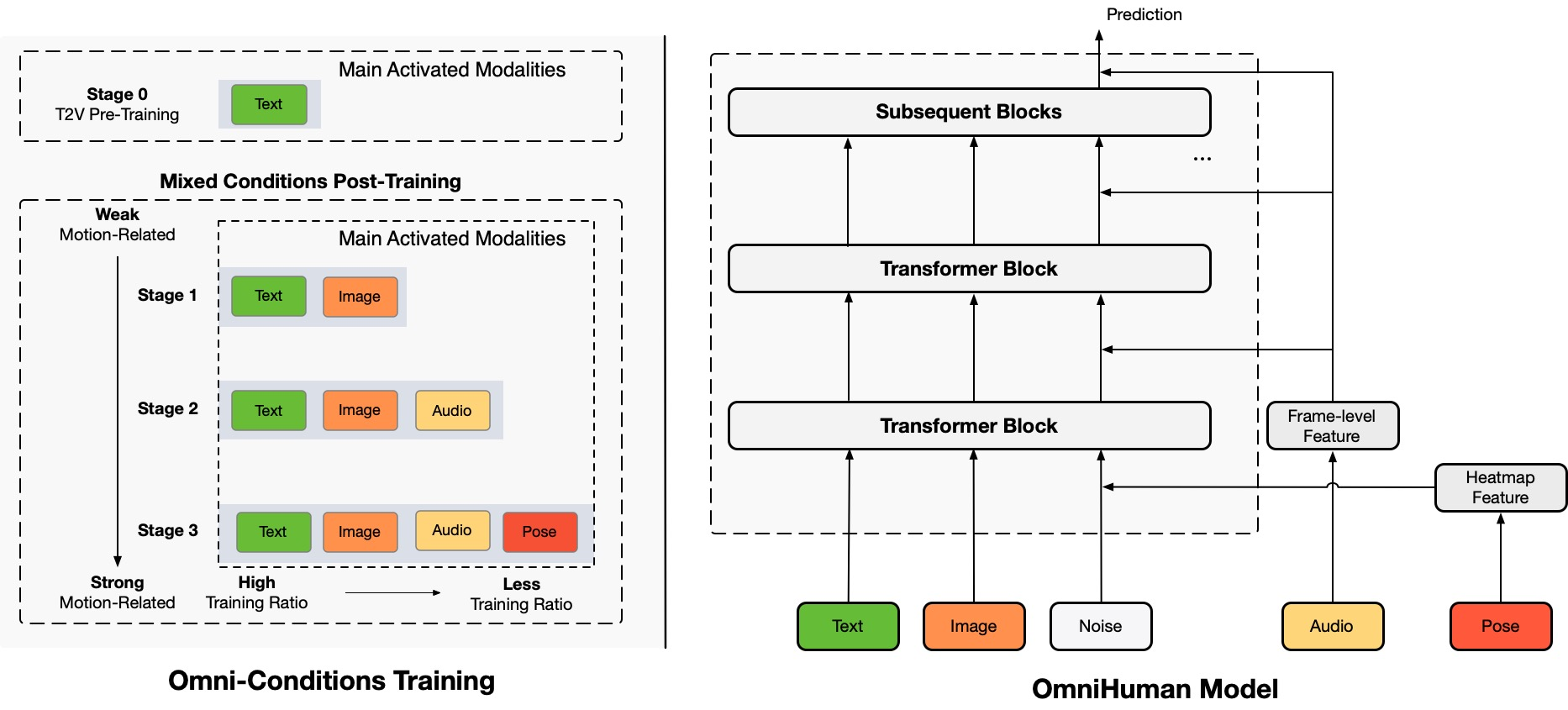
- Hybrid Condition Training Strategy:
- Multi-condition Fusion: Combines text, audio, and pose conditions in the training process to reduce data wastage and leverage the complementary nature of different conditions.
- Phased Training: Employs a three-phase training strategy, gradually introducing different conditions (text, audio, pose) and adjusting training ratios based on condition strength to optimize model generalization.
- Training Principle: Uses weaker conditions for stronger condition tasks to expand data scale. Stronger conditions should have lower training ratios to avoid over-reliance on strong conditions.
- Diffusion Transformer Architecture:
- DiT-based Model: OmniHuman is based on the advanced video generation model architecture DiT, using Causal 3DVAE to project videos into latent space and Flow Matching as the training objective.
- Condition Injection:
- Audio Condition: Uses the wav2vec model to extract audio features, combines them with video frame features to generate audio tokens, and injects them into the model via cross-attention mechanisms.
- Pose Condition: Uses a Pose Guider to process pose conditions, combines pose heatmap features with video frame features to generate pose tokens, and inputs them along with noise latent representations into the model.
- Text Condition: Retains the text branch in the DiT architecture for describing video content.
- Reference Condition Handling: Employs an innovative reference condition strategy based on modifying 3D rotation position embeddings (RoPE) to fuse reference image features with video features without additional network modules.
- Inference Strategy:
- Classifier-Free Guidance (CFG): Applies CFG to audio and text conditions during inference, gradually reducing CFG strength to balance expressiveness and computational efficiency, reducing flaws in generated videos (e.g., wrinkles).
- Long Video Generation: Uses the last few frames of a video clip as motion frames to ensure temporal coherence and identity consistency in long video generation.
Application Scenarios of OmniHuman
- Film and Entertainment: Generates virtual character animations, virtual hosts, and music videos, enhancing content production efficiency and visual effects.
- Game Development: Generates natural movements for game characters and NPCs, improving game immersion and interactivity.
- Education and Training: Creates virtual teachers and simulation training videos, aiding language learning and professional skill training.
- Advertising and Marketing: Generates personalized ads and brand promotion videos, increasing user engagement and content appeal.
- Social Media and Content Creation: Helps creators quickly produce high-quality short videos, supports interactive video creation, and adds fun to content.
Framework Features
Getting Started
Screenshots & Images

Helping everyone find the best AI for their work and daily life through deep analysis and honest comparisons.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









