
Ola
by Tsinghua University, Tencent Hunyuan Research Team, NUS S-LabWhat is Ola?
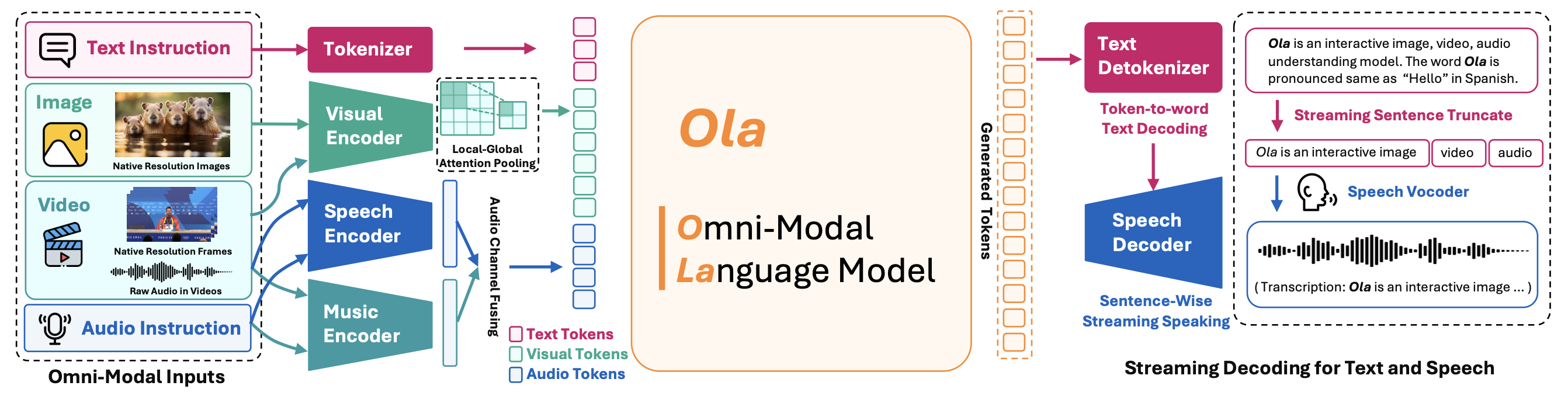
Ola is a full-modal language model developed in collaboration by Tsinghua University, Tencent Hunyuan Research Team, and NUS S-Lab. It employs a progressive modal alignment strategy to gradually expand the modalities supported by the language model, starting with images and text, and then introducing audio and video data, enabling comprehensive understanding of multiple modalities. Ola's architecture supports full-modal inputs, including text, images, video, and audio, and can process these inputs simultaneously. It also features a sentence-by-sentence decoding scheme for streaming speech generation, enhancing interactive experiences.
Key Features of Ola
- Multimodal Understanding: Supports inputs of text, images, video, and audio, and can process these inputs simultaneously, excelling in understanding tasks.
- Real-time Streaming Decoding: Supports user-friendly real-time streaming decoding for text and speech generation, providing a smooth interactive experience.
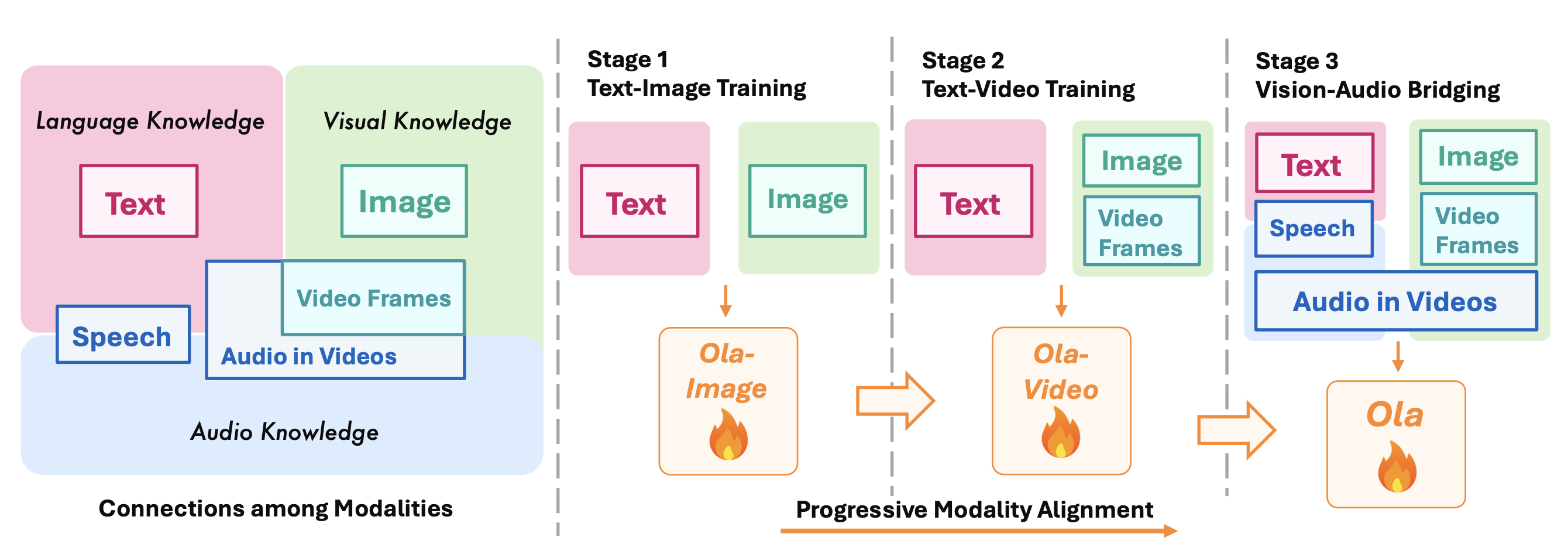
- Progressive Modal Alignment: Gradually expands the modalities supported by the language model, starting with images and text, and then introducing audio and video data, enabling comprehensive understanding of multiple modalities.
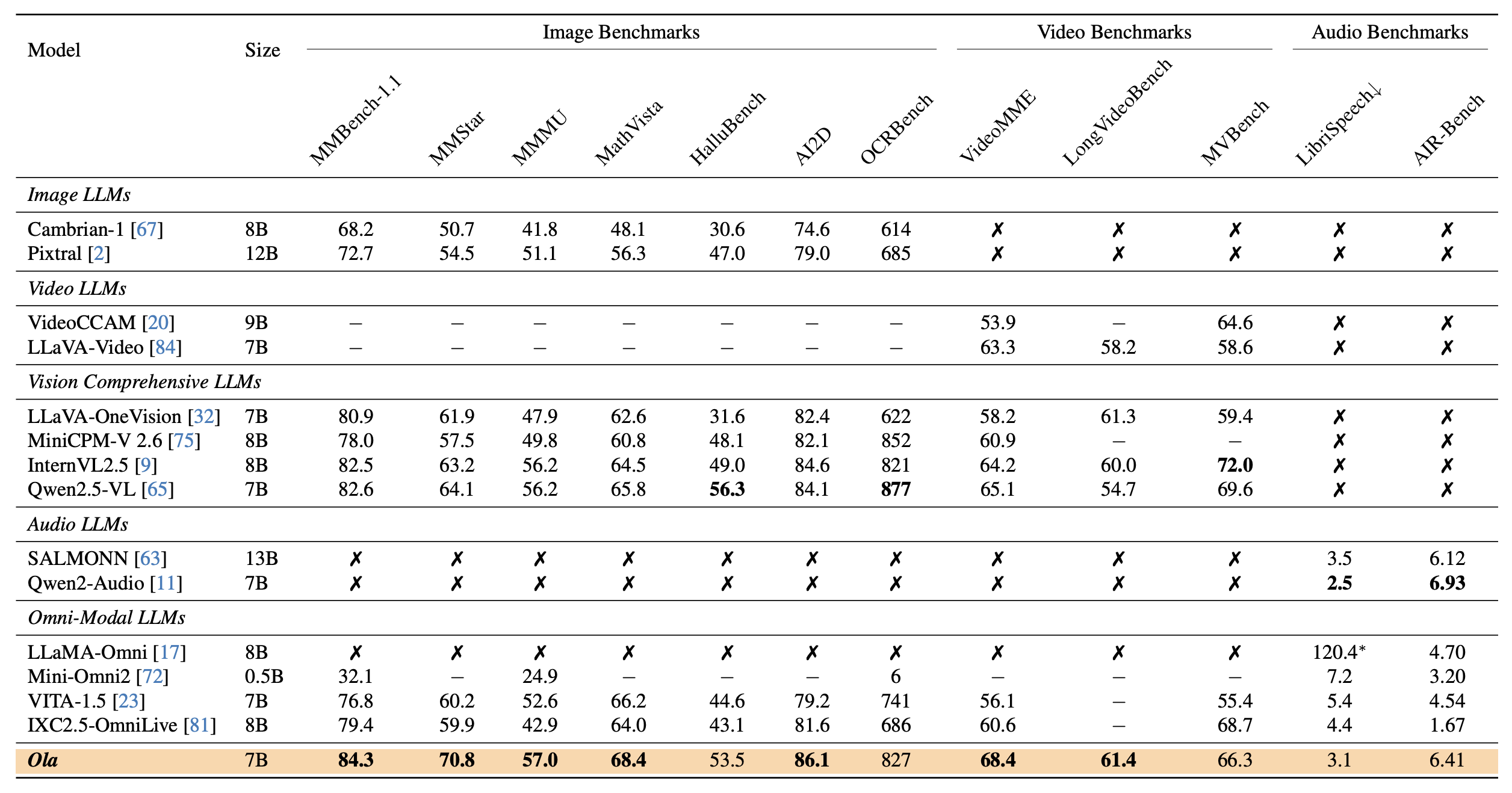
- High Performance: Demonstrates outstanding performance in multimodal benchmarks, surpassing existing open-source full-modal LLMs and matching specialized single-modal models in certain tasks.
Technical Principles of Ola
- Progressive Modal Alignment Strategy: Ola's training process starts with the most basic modalities (images and text) and gradually introduces audio data (linking language and audio knowledge) and video data (linking all modalities). This progressive learning approach allows the model to gradually expand its modal understanding capabilities, keeping the scale of cross-modal alignment data relatively small, reducing the difficulty and cost of developing full-modal models from existing visual-language models.
- Multimodal Input and Real-time Streaming Decoding: Ola supports full-modal inputs, including text, images, video, and audio, and can process these inputs simultaneously. It features a sentence-by-sentence decoding scheme for streaming speech generation, supporting user-friendly real-time interaction.
- Efficient Utilization of Cross-modal Data: To better capture the relationships between modalities, Ola's training data includes traditional visual and audio data, as well as designed cross-modal video-audio data. The data builds bridges through visual and audio information in videos, helping the model learn the intrinsic connections between modalities.
- High-performance Architecture Design: Ola's architecture supports efficient multimodal processing, including visual encoders, audio encoders, text decoders, and speech decoders. Through technologies like Local-Global Attention Pooling, the model can better integrate features from different modalities.
Ola Project Address
- Project Website: https://ola-omni.github.io/
- Github Repository: https://github.com/Ola-Omni/Ola
- arXiv Technical Paper: https://arxiv.org/pdf/2502.04328
Application Scenarios of Ola
- Intelligent Voice Interaction: Ola can serve as an intelligent voice assistant, supporting multilingual speech recognition and generation. Users can interact with Ola through voice commands to obtain information, solve problems, or complete tasks.
- Education and Learning: Ola can be used as an English practice tool, helping users practice speaking, correct pronunciation, and grammar errors. It can also provide encyclopedia Q&A, covering learning scenarios from K12 to the workplace.
- Travel and Navigation: Ola can serve as a travel guide, providing users with historical and cultural background information about tourist attractions, and recommending travel guides and dining options.
- Emotional Companionship: Ola can provide emotional chat services, helping users relieve stress and offer psychological support.
- Life Services: Ola can recommend nearby dining options, provide schedule management, and travel navigation services.
Model Capabilities
Usage & Integration
Screenshots & Images

Stats
Community & Support
Similar Models
The AI discovery platform. Deep analysis, honest comparisons, and real metrics to help you find the best AI for any task.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









