DynVFX
What is DynVFX?
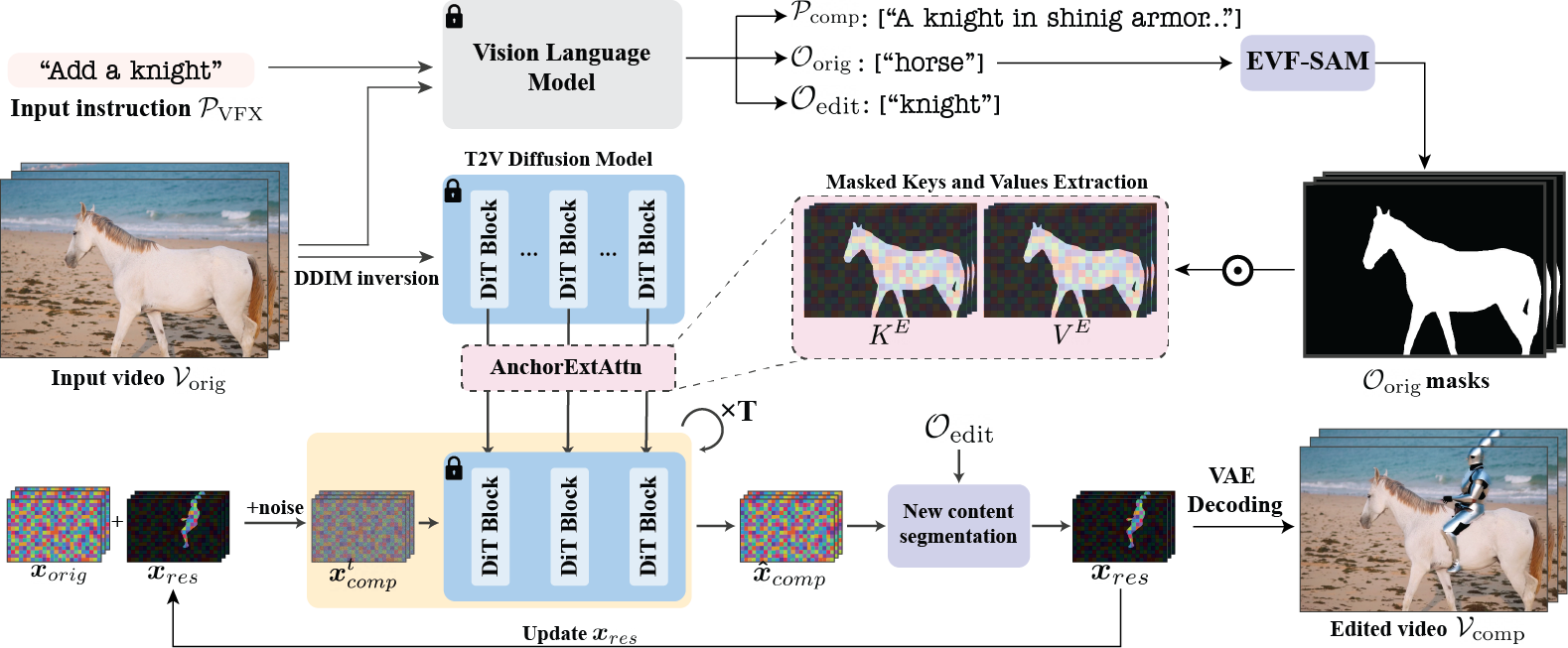
DynVFX is an innovative video enhancement technology that seamlessly integrates dynamic content into real videos based on simple text instructions. By combining pre-trained text-to-video diffusion models and visual language models (VLM), it naturally integrates new dynamic elements into the original video scene without relying on complex user input. Users only need to provide short text instructions, such as "Add a dolphin swimming in the water," and DynVFX automatically parses the instruction, generates detailed scene descriptions based on VLM, precisely locates the position of new content through anchor extended attention mechanisms, and ensures pixel-level alignment and natural integration with the original video through iterative refinement.
Main Features of DynVFX
- Natural Integration of New Dynamic Elements: DynVFX can naturally integrate newly generated dynamic content into the original video scene based on user-provided text instructions (e.g., "Add a whale flying in the air"). The position, appearance, and motion of the new content are consistent with the camera motion, occlusion, and interaction with other dynamic objects in the original video, resulting in a coherent and realistic output video.
- Automated Content Generation and Positioning: Automation is achieved through pre-trained text-to-video diffusion models and visual language models (VLM). VLM acts as a "VFX assistant," understanding user instructions and generating detailed scene descriptions to guide the generation of new content. DynVFX uses anchor extended attention mechanisms to precisely locate the position of new content, aligning it with the spatial and dynamic features of the original scene.
- Pixel-Level Alignment and Content Integration: DynVFX ensures pixel-level alignment with the original video through an iterative refinement process, gradually updating the residual latent representation of the new content to avoid unnatural transitions or misalignment.
- High-Fidelity Video Editing: While preserving the original video content, DynVFX can naturally add new dynamic elements, achieving high-fidelity video editing.
Technical Principles of DynVFX
- Pre-trained Text-to-Video Diffusion Models: DynVFX uses pre-trained text-to-video diffusion models (e.g., CogVideoX) to generate video content based on text prompts. The diffusion model generates video by gradually removing noise, starting from Gaussian noise and progressively generating clear video frames.
- Visual Language Model (VLM): Visual language models (e.g., GPT-4o) are used as "VFX assistants," interpreting user text instructions and generating detailed scene descriptions. VLM describes the content of the original video and provides guidance on how to naturally integrate new content into the scene.
- Anchor Extended Attention: To ensure accurate positioning of newly generated content, DynVFX introduces an anchor extended attention mechanism. By extracting specific keys and values from the original video, they are used as anchors to guide the generation of new content. This helps the model understand how the new content should align with the spatial and dynamic features of the original scene, achieving natural integration.
- Iterative Refinement: To further improve the integration of new content with the original video, DynVFX employs an iterative refinement method. Specifically, the model updates the residual latent representation through multiple iterations, gradually reducing noise levels. Each iteration adjusts the details of the new content to better align with the original video, achieving pixel-level precise integration.
- Residual Estimation and Update: DynVFX adjusts the difference between the new content and the original video by estimating a residual. The residual represents the difference between the newly generated content and the original video, and by iteratively updating the residual, the model can gradually optimize the generation of new content, seamlessly integrating it with the original video.
- Zero-Shot, No Fine-Tuning Required: DynVFX uses a zero-shot approach, requiring no additional fine-tuning or training of the pre-trained text-to-video model. Users only need to provide simple text instructions to achieve high-quality video editing.
- Automated Evaluation: To evaluate the quality of the generated video, DynVFX introduces VLM-based automated evaluation metrics. The metrics assess the quality of the generated video from multiple aspects, including the preservation of the original content, the integration of new content, overall visual quality, and dynamic effects.
DynVFX Project Address
- Project Website: https://dynvfx.github.io/
- arXiv Technical Paper: https://arxiv.org/pdf/2502.03621
Application Scenarios of DynVFX
- Video Special Effects Production: Quickly add special effects such as fire, water flow, and magic effects to movies, TV shows, advertisements, and other video content.
- Content Creation: Help creators add creative elements to existing videos, enhancing the appeal and interest of the video.
- Education and Training: Add dynamic annotations or demonstration effects to educational videos to enhance the learning experience.
Features & Capabilities
Getting Started
Screenshots & Images

Stats
Similar Tools
The AI discovery platform. Deep analysis, honest comparisons, and real metrics to help you find the best AI for any task.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









