VidTok
by MicrosoftWhat is VidTok?
VidTok (Video Tokenizer) is an advanced video tokenizer developed by Microsoft. It efficiently converts video content into a series of "video tokens" using high-performance algorithms. It supports both continuous and discrete tokenization, offering flexible compression rates and diverse latent spaces, making it suitable for various application scenarios. VidTok employs a hybrid model architecture that combines convolutional layers and up/down-sampling modules to reduce computational complexity while maintaining high-quality reconstruction. It also introduces finite scalar quantization technology to address training instability and codebook collapse issues in traditional vector quantization.
Key Features of VidTok
- Video Tokenization: VidTok can convert high-dimensional video data (such as images and video frames) into more compact visual tokens.
- Efficient Compression: VidTok works under different compression rate settings, effectively compressing video data while maintaining video quality.
- Continuous and Discrete Tokenization: VidTok supports both continuous and discrete tokenization methods, adapting to different models and application needs.
- Causal and Non-Causal Model Support: VidTok supports both causal and non-causal models. Causal models rely only on historical frames for tokenization, while non-causal models can use both historical and future frame information.
- Diverse Latent Space Support: VidTok supports latent spaces of different sizes, adapting to various video compression rates and model complexities.
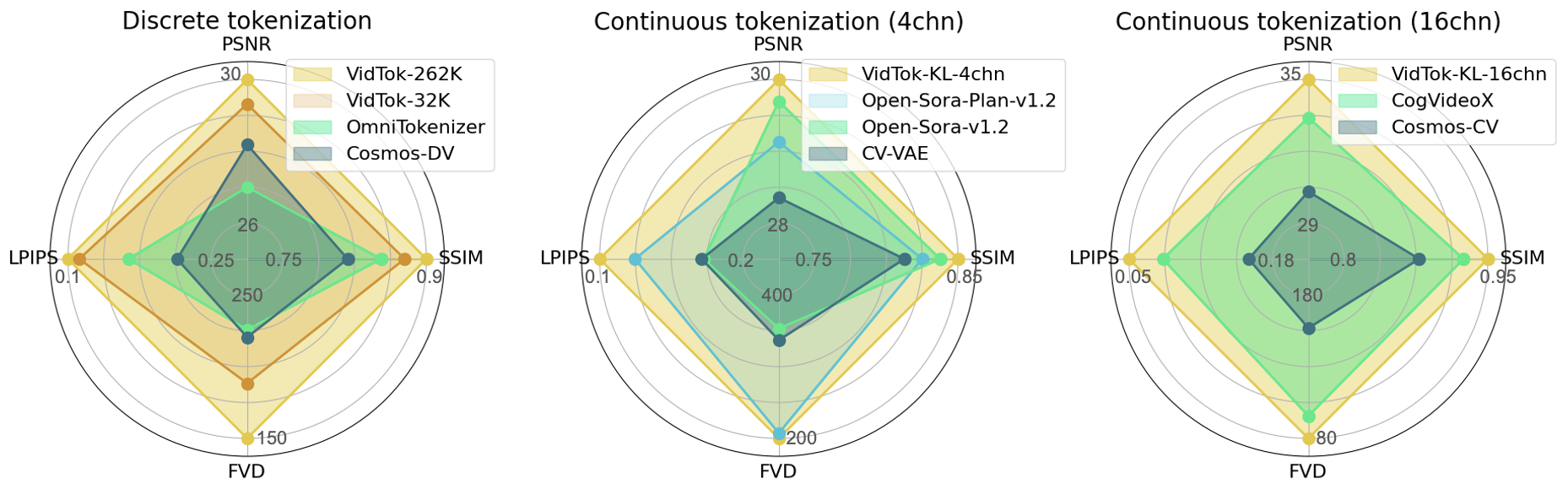
- High-Performance Reconstruction: VidTok excels in multiple video quality assessment metrics, including PSNR, SSIM, FVD, and LPIPS, providing high-quality video reconstruction.
Technical Principles of VidTok
- Efficient Hybrid Model Architecture Design: VidTok adopts a classic 3D encoder-decoder structure and innovatively combines 3D, 2D, and 1D convolutions to effectively decouple spatial and temporal sampling.
- Advanced Quantization Technology: VidTok introduces finite scalar quantization (FSQ) technology, a quantization method that does not require explicit codebook learning, significantly improving model training stability and reconstruction performance.
- Enhanced Training Strategy: VidTok uses a phased training strategy, first pre-training the complete model on low-resolution videos and then fine-tuning the decoder on high-resolution videos.
Project Addresses of VidTok
- Github Repository: https://github.com/microsoft/vidtok
- HuggingFace Model Library: https://huggingface.co/microsoft/VidTok
- arXiv Technical Paper: https://arxiv.org/pdf/2412.13061
Application Scenarios of VidTok
- Video Generation: VidTok can be used in video generation models, such as Sora and Genie. The model converts high-dimensional video data into compact visual tokens based on the tokenizer, and then trains the generation model with these tokens as targets.
- Efficient Video Content Modeling: Video generation and video-based world models are hot research directions in the field of artificial intelligence. VidTok provides an efficient intermediate medium for model understanding of the world through efficient video content modeling.
- Video Data Compression and Representation: Due to the high redundancy of pixel-level representation of video data, VidTok reduces the computational requirements for model training and inference through efficient video data compression and representation.
Framework Features
Getting Started
Screenshots & Images




Stats
Community & Support
Similar Frameworks
Recently Viewed
Helping everyone find the best AI for their work and daily life through deep analysis and honest comparisons.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









