CogVideoX
by Zhipu AIWhat is CogVideoX?
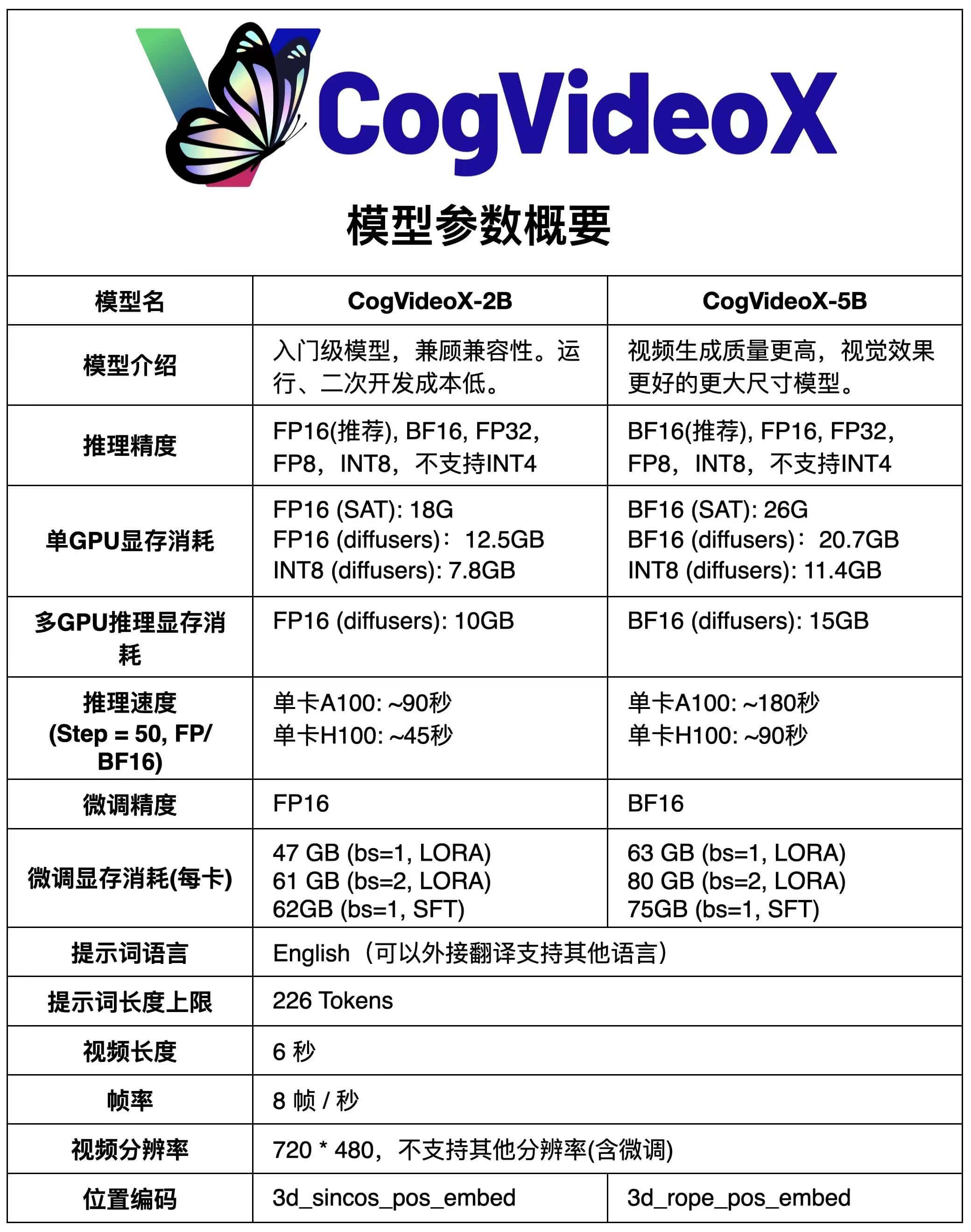
CogVideoX is an open-source AI video generation model developed by Zhipu AI. It allows users to generate 6-second videos from English text prompts, with a resolution of 720*480 and 8 frames per second. The model requires 7.8-26GB of VRAM for inference and includes features like 3D Causal VAE for video reconstruction. It also provides tools such as CLI/WEB Demo, online experience, API interface examples, and fine-tuning guides.
Main Features of CogVideoX
- AI Text-to-Video Generation: Supports generating video content from user-input text prompts.
- Low VRAM Requirement: With INT8 precision, the inference VRAM requirement is only 7.8GB, allowing even a 1080 Ti graphics card to complete the inference.
- Customizable Video Parameters: Allows customization of video length, frame rate, and resolution. Currently supports 6-second videos with 8 frames per second and a resolution of 720*480.
- 3D Causal VAE Technology: Uses 3D Causal VAE technology for efficient video reconstruction.
- Inference and Fine-Tuning: The model supports basic video generation through inference and also provides fine-tuning capabilities to adapt to different needs.
Technical Principles of CogVideoX
- Text-to-Video Generation: CogVideoX uses deep learning models, particularly Transformer-based architectures, to understand input text prompts and generate video content.
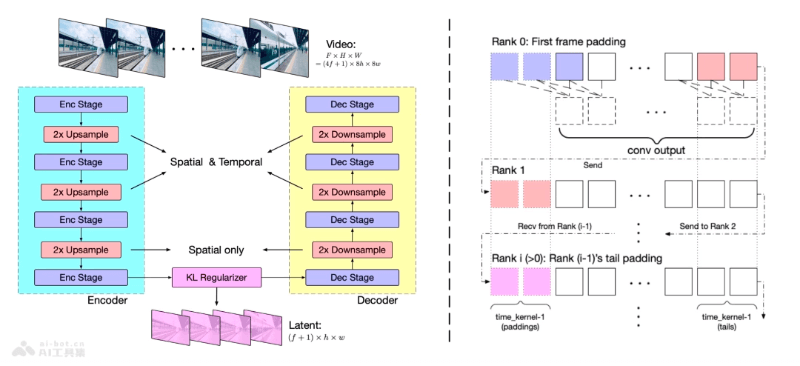
- 3D Causal VAE: CogVideoX employs 3D Causal Variational Autoencoder (VAE), a technology for video reconstruction and compression, enabling almost lossless video reconstruction while reducing storage and computational requirements.
- Expert Transformer: CogVideoX uses an Expert Transformer model, a specialized Transformer that processes different tasks through multiple experts, such as spatial and temporal information processing and controlling information flow.
- Encoder-Decoder Architecture: In the 3D VAE, the encoder converts videos into simplified codes, and the decoder reconstructs videos based on these codes. A latent space regularizer ensures more accurate information transfer between encoding and decoding.
- Mixed Duration Training: CogVideoX's training process employs mixed duration training, allowing the model to learn videos of different lengths and improve generalization.
- Multi-Stage Training: CogVideoX's training is divided into several stages, including low-resolution pre-training, high-resolution pre-training, and high-quality video fine-tuning, gradually improving the model's generation quality and details.
- Automatic and Manual Evaluation: CogVideoX uses a combination of automatic and manual evaluation to ensure the generated video quality meets expectations.
Project Addresses of CogVideoX
- Zhipu Qingying Experience: https://ai-bot.cn/chatglm-video/
- CogVideoX-2B Model Address:
- HuggingFace Model Library: https://huggingface.co/THUDM/CogVideoX-2b
- ModelScope Community Model Library: https://modelscope.cn/models/ZhipuAI/CogVideoX-2b
- CogVideoX-5B Model Address:
- HuggingFace Model Library: https://huggingface.co/spaces/THUDM/CogVideoX-5B
- ModelScope Community Model Library: https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
- GitHub Repository: https://github.com/THUDM/CogVideo
- arXiv Technical Paper: https://arxiv.org/pdf/2408.06072
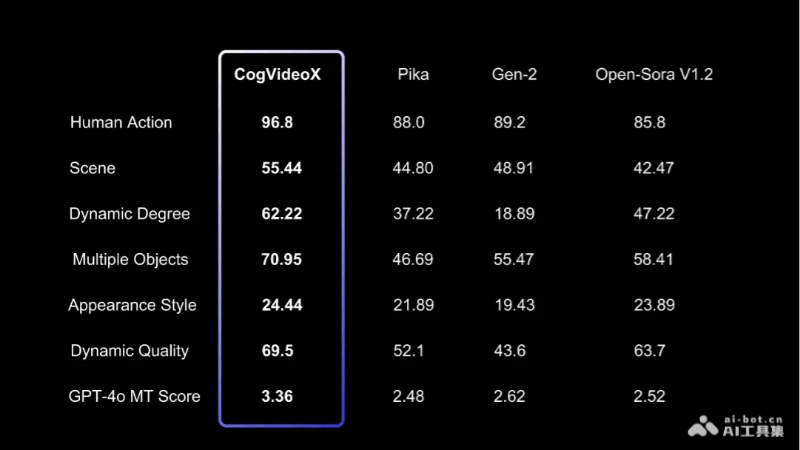
Performance Evaluation of CogVideoX
To evaluate the quality of text-to-video generation, we used multiple metrics from VBench, such as human action, scene, and dynamic level. We also used two additional video evaluation tools: Devil's Dynamic Quality and Chrono-Magic's GPT4o-MT Score, which focus on the dynamic characteristics of videos. The results are shown in the table below.
Application Scenarios of CogVideoX
- Creative Video Production: Provides tools for independent video creators and artists to quickly transform creative text descriptions into visual video content.
- Educational and Training Materials: Automates the generation of educational videos to help explain complex concepts or demonstrate teaching scenarios.
- Advertising and Brand Promotion: Companies can use the CogVideoX model to generate video ads based on advertising copy, improving marketing effectiveness.
- Gaming and Entertainment Industry: Assists game developers in quickly generating in-game animations or story videos, enhancing the gaming experience.
- Film and Video Editing: Assists video editing work by generating specific scenes or special effects videos based on text descriptions.
- Virtual Reality (VR) and Augmented Reality (AR): Generates immersive video content for VR and AR applications, enhancing user interaction experiences.
Model Capabilities
Usage & Integration
- 7.8-26GB VRAM
- GPU
Screenshots & Images