CosyVoice2
by Alibaba GroupCosyVoice 2.0 is an upgraded version of Alibaba's speech generation model, enhancing pronunciation accuracy, timbre consistency, and audio quality with advanced quantization and streaming synthesis capabilities.
CosyVoice 2.0
What is CosyVoice 2.0?
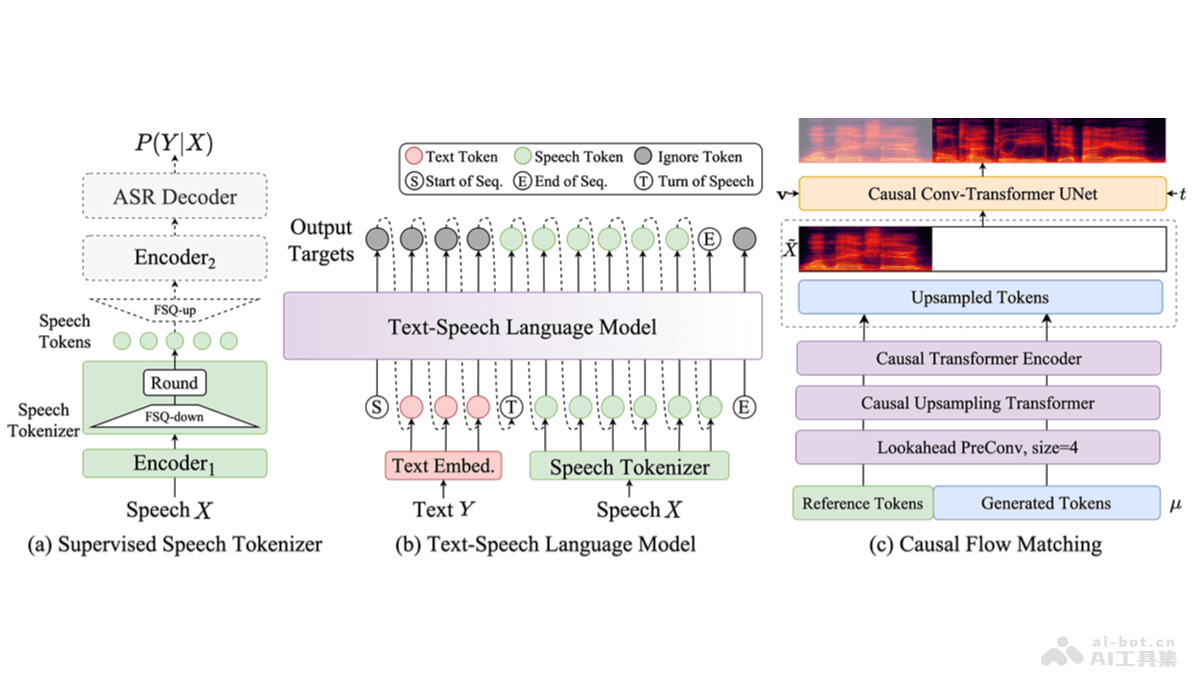
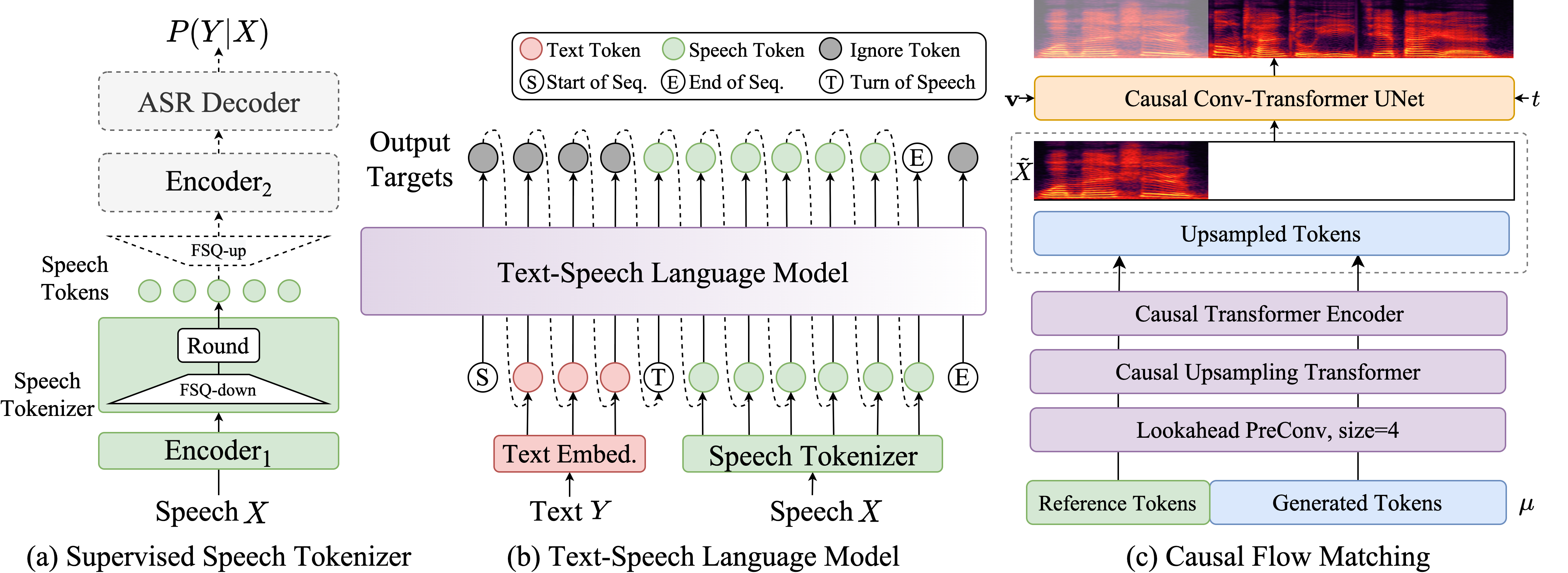
CosyVoice 2.0 is an upgraded version of the CosyVoice speech generation model developed by Alibaba's Tongyi Lab. The model improves codebook utilization with limited scalar quantization, simplifies the text-to-speech architecture, and introduces a block-aware causal flow matching model to support diverse synthesis scenarios. CosyVoice 2.0 significantly enhances pronunciation accuracy, timbre consistency, rhythm, and audio quality, with a MOS score increase from 5.4 to 5.53. It supports streaming inference, reducing the first-packet synthesis latency to 150ms, making it suitable for real-time speech synthesis applications.
Key Features of CosyVoice 2.0
- Ultra-low Latency Streaming Speech Synthesis: Supports bidirectional streaming speech synthesis with a first-packet latency of 150ms, ideal for real-time applications.
- High Pronunciation Accuracy: Significantly reduces pronunciation errors, especially in handling tongue twisters, polyphonic characters, and rare characters.
- Timbre Consistency: Maintains high timbre consistency in zero-shot and cross-language speech synthesis, enhancing naturalness.
- Natural Experience: Improves rhythm, audio quality, and emotional matching in synthesized audio, with an increased MOS score, approaching commercial speech synthesis models.
- Multilingual Support: Trained on a large-scale multilingual dataset, enabling cross-language speech synthesis capabilities.
Technical Principles of CosyVoice 2.0
- LLM Backbone: Based on pre-trained text foundation models (e.g., Qwen2.5-0.5B), replacing the original Text Encoder + random Transformer structure for semantic modeling.
- FSQ Speech Tokenizer: Uses Full Scale Quantization (FSQ) instead of Vector Quantization (VQ), training a larger codebook (6561) with 100% activation, improving pronunciation accuracy.
- Unified Offline and Streaming Modeling: Introduces a unified modeling approach, enabling both LLM and FM to support streaming inference for rapid first-packet audio synthesis.
- Instruction-Controlled Audio Generation: Optimizes the integration of base and instruction models, supporting emotion, speaking style, and fine-grained control instructions, with added Chinese instruction processing capabilities.
- Multimodal Model Technology: Based on multimodal model technology, integrating speech recognition, speech synthesis, and natural language understanding for intelligent human-computer interaction.
Project Links for CosyVoice 2.0
- Official Website: https://funaudiollm.github.io/cosyvoice2/
- GitHub Repository: https://github.com/FunAudioLLM/CosyVoice
- Technical Paper: https://funaudiollm.github.io/pdf/CosyVoice_2.pdf
Application Scenarios of CosyVoice 2.0
- Smart Assistants and Chatbots: Provides natural and fluent speech output for smart assistants and chatbots, enhancing user experience.
- Audiobooks and Audio Books: Generates high-quality audiobooks, supporting multiple languages and dialects to meet diverse user needs.
- Video Dubbing and Narration: Offers dubbing services for video content, including educational videos, corporate promotional videos, and movie/TV show dubbing.
- Customer Service and Call Centers: Enables voice interaction in customer service, improving efficiency and customer satisfaction.
- Language Learning and Education: Assists in language learning by providing standard pronunciation examples, helping learners improve pronunciation accuracy.
Model Capabilities
Model Type
Speech Generation
Supported Tasks
Text-To-Speech
Streaming Speech Synthesis
Multilingual Speech Synthesis
Zero-Shot Voice Generation
Cross-Language Speech Synthesis
Tags
Speech Synthesis
AI Model
Real-time Processing
Multilingual Support
Text-to-Speech
Streaming Inference
High Accuracy
Timbre Consistency
Natural Experience
Low Latency
Usage & Integration
Pricing
free
License
Open Source
Screenshots & Images
Primary Screenshot
Additional Images