CSM
by Sesame TeamCSM is a conversational speech model developed by Sesame Team, enhancing the naturalness and emotional interaction capabilities of voice assistants.
What is CSM?
CSM (Conversational Speech Model) is a voice dialogue model developed by the Sesame Team, designed to improve the naturalness and emotional interaction capabilities of voice assistants. It uses a multimodal learning framework, combining text and voice data, and leverages the Transformer architecture to generate natural and coherent speech.
Main Features of CSM
- Emotional Expression: Adjusts the tone, rhythm, and emotional color of speech based on conversation content and emotional context, making interactions more engaging.
- Natural Conversation: Generates more natural and coherent voice responses by understanding conversation history and context, avoiding mechanical replies.
- Contextual Adaptation: Adjusts voice style according to different scenarios (e.g., formal, casual, comforting, motivating) to enhance the appropriateness of interactions.
- Multimodal Interaction: Combines text and voice input to generate high-quality voice output, supporting more complex dialogue structures.
- Low Latency Generation: Optimized architecture enables low-latency voice generation, suitable for real-time conversation scenarios.
- Multilingual Support: Currently focuses on English, with plans to expand to multiple languages in the future, improving cross-language interaction capabilities.
Technical Principles of CSM
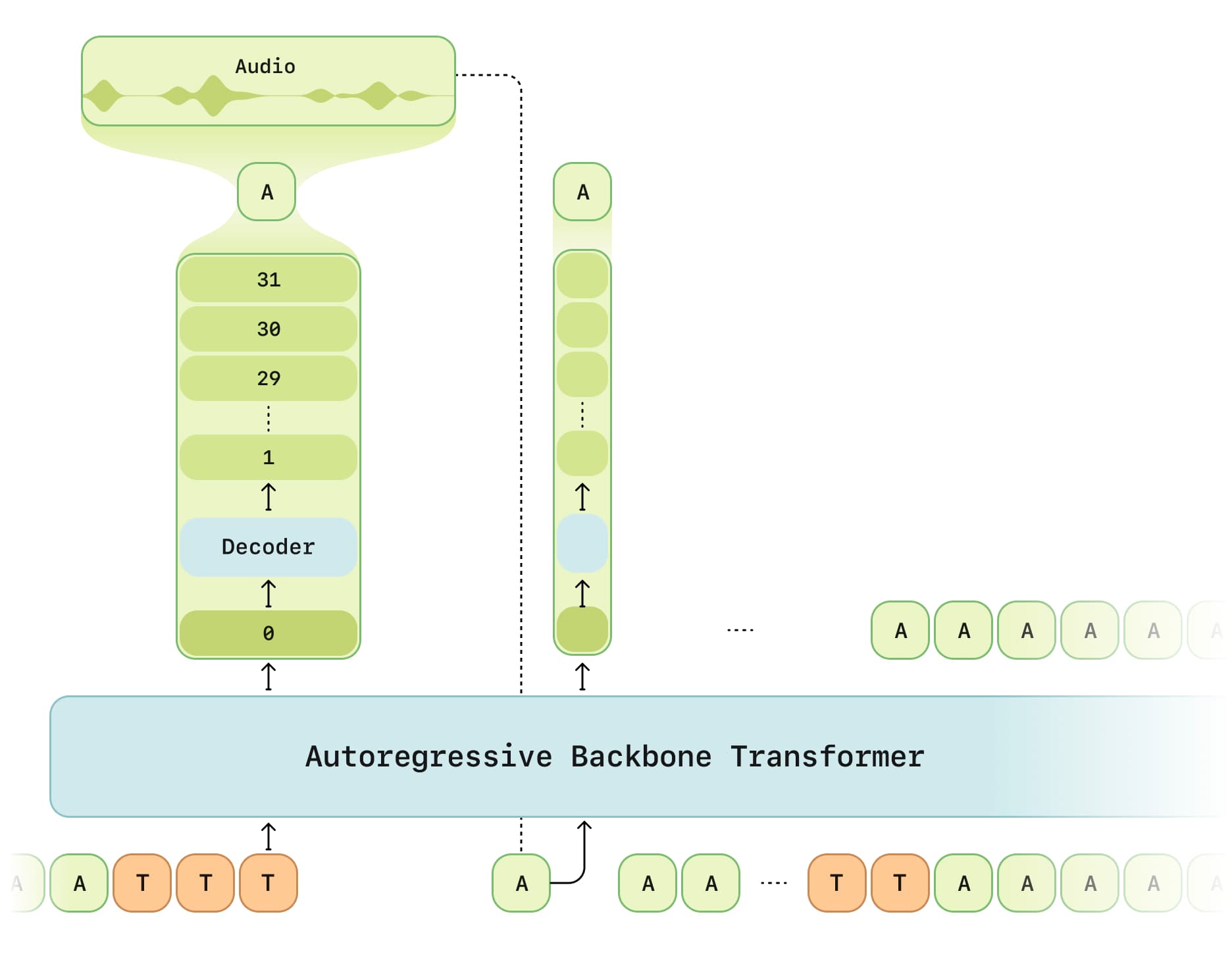
- Multimodal Transformer Architecture: CSM combines text and voice data, processed by two autoregressive Transformer models. The first "Backbone" model handles zero-level encoding of text and voice (semantic information), while the second "Decoder" model processes the remaining audio encoding (acoustic details), achieving end-to-end voice generation.
- Residual Vector Quantization (RVQ): Uses RVQ technology to encode continuous audio waveforms into discrete audio token sequences, including semantic tokens and acoustic tokens. Semantic tokens capture high-level features of speech, while acoustic tokens retain the details of natural speech.
- Conversation History Modeling: CSM models conversation history to capture contextual information, generating voice responses that better fit the conversation scenario.
- Computational Amortization: To address the high memory burden during training, CSM uses computational amortization techniques to train the decoder on partial audio frames while retaining full RVQ encoding, significantly improving training efficiency.
- Real-Time Interaction Optimization: Optimized model architecture and training strategies enable CSM to generate voice with low latency, suitable for real-time conversation scenarios.
Application Scenarios of CSM
- Smart Voice Assistants: Enhances the interaction quality of voice assistants in smart home and office devices, enabling more natural and emotional conversations with users, improving user experience.
- Customer Service and Support: Generates natural and fluent voice responses in call centers and online customer service, understanding customer emotions and providing personalized services to increase customer satisfaction.
- Education and Learning Tools: Offers more natural voice interaction for language learning software and online education platforms, helping learners imitate and practice language expression, improving learning outcomes.
- Entertainment and Gaming: Endows characters in voice interaction games, audiobooks, and virtual roles with rich emotions and personalities, enhancing user immersion and engagement.
- Accessibility Assistive Technology: Provides more natural and understandable voice feedback for visually impaired or reading-disabled individuals, helping users access information and interact more conveniently.
Model Capabilities
Model Type
multimodal
Supported Tasks
Voice Generation
Emotional Speech Synthesis
Conversational Ai
Real-Time Interaction
Multilingual Support
Tags
Conversational AI
Voice Assistants
Multimodal Learning
Transformer Architecture
Emotional Interaction
Natural Language Processing
Speech Generation
Real-Time Interaction
Multilingual Support
Contextual Adaptation
Usage & Integration
Screenshots & Images
Primary Screenshot
Additional Images
Stats
229
Views
0
Favorites









