FunAudioLLM
by Alibaba Tongyi LabFunAudioLLM is an open-source speech large model project by Alibaba Tongyi Lab, featuring SenseVoice for multilingual speech recognition and CosyVoice for natural speech generation.
What is FunAudioLLM?
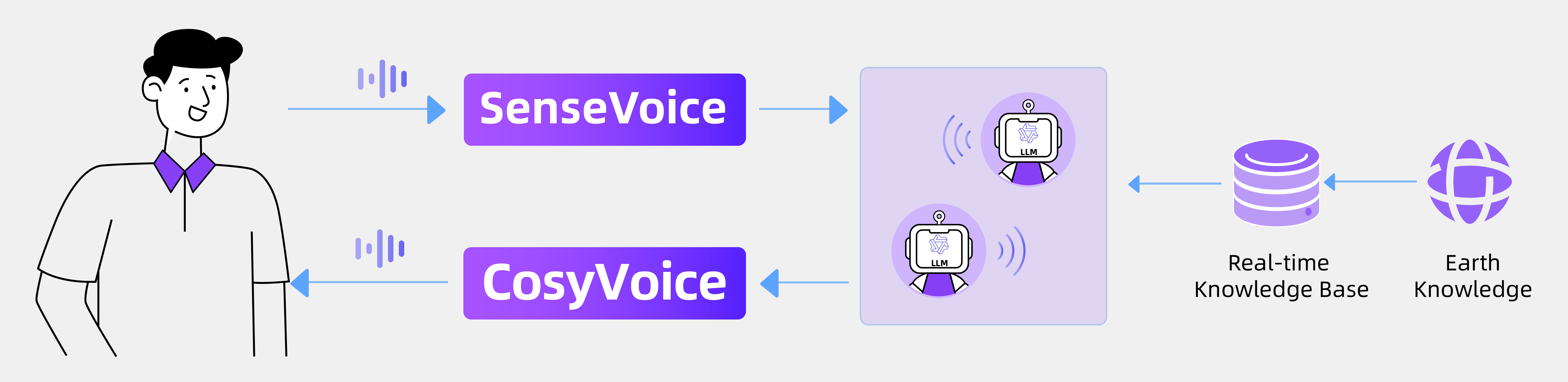
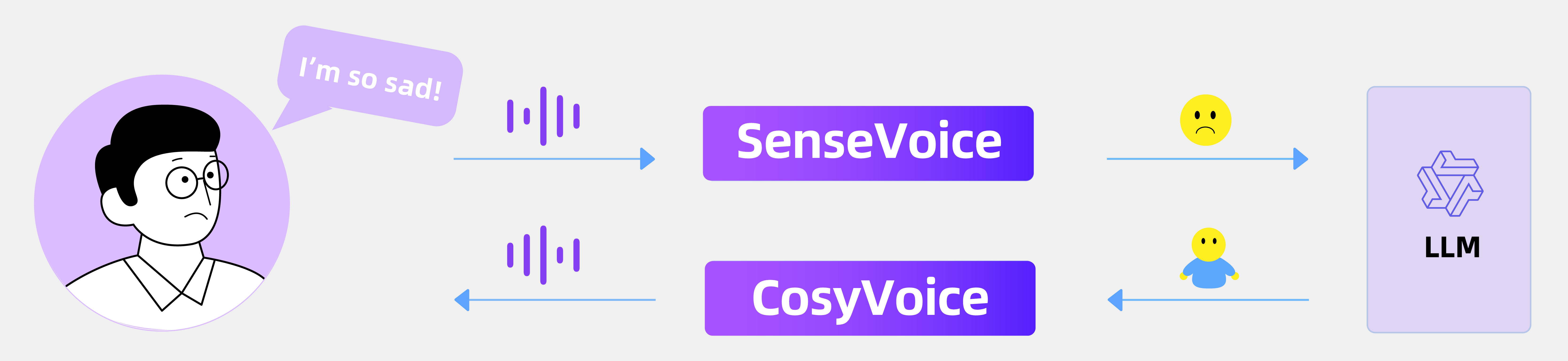
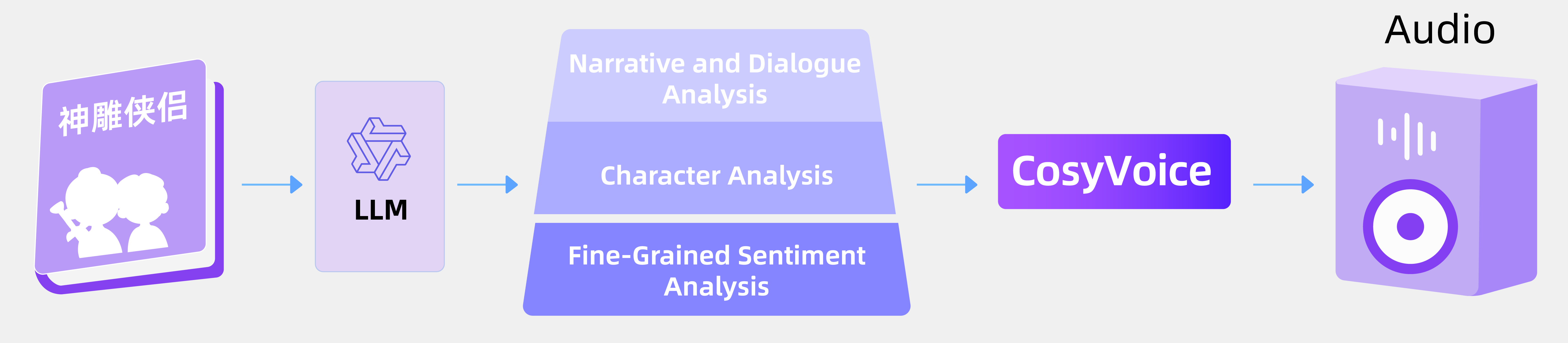
FunAudioLLM is an open-source speech large model project developed by Alibaba Tongyi Lab, consisting of two models: SenseVoice and CosyVoice. SenseVoice excels in multilingual speech recognition and emotion detection, supporting over 50 languages, with particularly strong performance in Chinese and Cantonese. CosyVoice focuses on natural speech generation, capable of controlling tone and emotion, and supports Chinese, English, Japanese, Cantonese, and Korean. FunAudioLLM is suitable for scenarios such as multilingual translation and emotional voice dialogue. The related models and code have been open-sourced on the Modelscope and Huggingface platforms.
Main Features of FunAudioLLM
- SenseVoice Model:
- Focuses on high-accuracy multilingual speech recognition.
- Supports over 50 languages, with superior recognition performance in Chinese and Cantonese.
- Features emotion detection, capable of identifying various human-computer interaction events.
- Offers both lightweight and large versions to adapt to different application scenarios.
- CosyVoice Model:
- Focuses on natural speech generation, supporting multilingual, tone, and emotion control.
- Can quickly generate simulated tones based on a small amount of original audio, including rhythm and emotional details.
- Supports cross-language speech generation and fine-grained emotion control.
Project Addresses of FunAudioLLM
- Project Official Website: https://fun-audio-llm.github.io/
- CosyVoice Online Experience: https://www.modelscope.cn/studios/iic/CosyVoice-300M
- SenseVoice Online Experience: https://www.modelscope.cn/studios/iic/SenseVoice
- GitHub Repository: https://github.com/FunAudioLLM
- arXiv Technical Paper: https://arxiv.org/abs/2407.04051
Application Scenarios of FunAudioLLM
- Developers and Researchers: Use FunAudioLLM for research and development in speech recognition, speech synthesis, and emotion analysis.
- Enterprise Users: Apply FunAudioLLM in customer service, intelligent assistants, and multilingual translation to improve efficiency and user experience.
- Content Creators: Use FunAudioLLM to generate audiobooks or podcasts, enriching content forms and attracting more listeners.
- Education Sector: Utilize FunAudioLLM for language learning and listening training to enhance learning efficiency and interest.
- People with Disabilities: Assist visually impaired individuals in accessing information through voice interaction, improving life convenience.
Model Capabilities
Model Type
speech
Supported Tasks
Multilingual Speech Recognition
Speech Synthesis
Emotion Detection
Voice Generation
Audio Event Detection
Tags
Speech Recognition
Speech Synthesis
Multilingual
Emotion Detection
Open Source
AI Models
Natural Language Processing
Voice Interaction
Machine Learning
Developer Tools
Usage & Integration
Pricing
free
License
Open Source
Open Source
Screenshots & Images
Primary Screenshot
Additional Images
Stats
96
Views
0
Favorites









