GeminiEmbedding
by GoogleGemini Embedding is an advanced text embedding model by Google that converts text into high-dimensional vectors to capture semantic and contextual information.
What is Gemini Embedding?
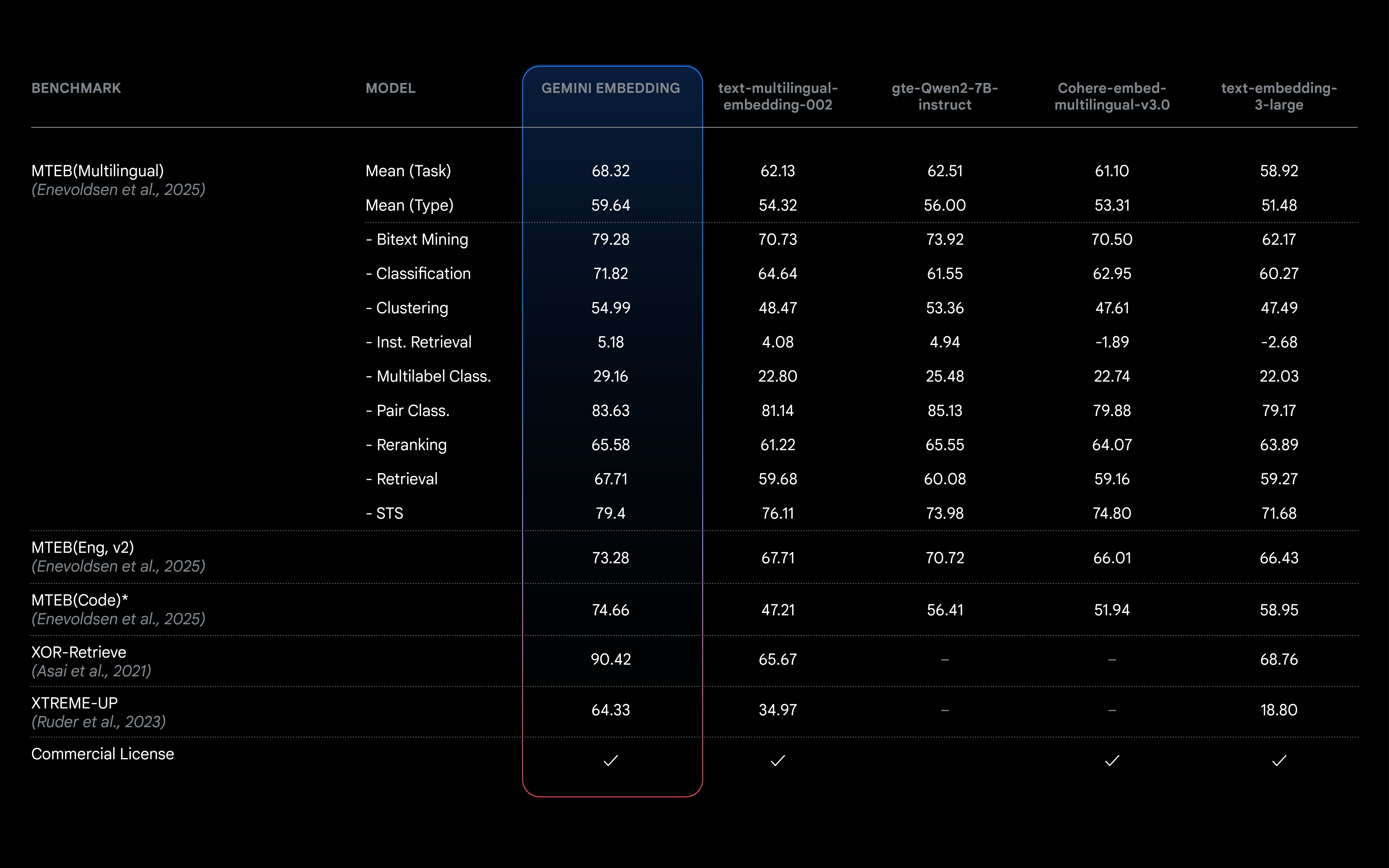
Gemini Embedding is an advanced text embedding model developed by Google, designed to transform text into high-dimensional numerical vectors that capture semantic and contextual information. Trained on the Gemini model, it excels in language understanding, supports over 100 languages, and ranks first in the Multilingual Text Embedding Benchmark (MTEB).
Key Features
- Efficient Retrieval: Quickly find relevant documents by comparing query and document embedding vectors.
- Retrieval-Augmented Generation (RAG): Improve the quality and relevance of generated text by combining contextual information.
- Text Clustering and Classification: Group similar texts, identify trends, and classify texts automatically.
- Text Similarity Detection: Identify duplicate content for web deduplication or plagiarism detection.
- Multilingual Support: Supports over 100 languages, making it suitable for cross-language applications.
- Flexible Dimension Adjustment: Adjust the dimension of embedding vectors to optimize storage costs.
- Long Text Embedding: Supports input tokens up to 8K in length, enabling the processing of longer texts, code, or data blocks.
Technical Principles
- Training Based on the Gemini Model: Leverages the deep language understanding and contextual awareness of the Gemini model.
- High-Dimensional Embedding Representation: Outputs 3K-dimensional embedding vectors for finer semantic capture.
- Matryoshka Representation Learning (MRL): Allows truncation of high-dimensional embedding vectors to reduce storage costs while maintaining semantic integrity.
- Contextual Awareness: Accurately captures semantics in complex multilingual environments.
- Optimized Input and Output: Supports long input tokens and provides rich semantic representation.
Application Scenarios
- Developers: Build intelligent search, recommendation systems, or natural language processing applications.
- Data Scientists: Use for text classification, clustering, and sentiment analysis.
- Enterprise Technology Teams: Use for knowledge management, document retrieval, and customer support.
- Researchers: Conduct linguistic research and multilingual analysis.
- Product Teams: Develop personalized content and intelligent interactive features.
Model Capabilities
Model Type
language
Supported Tasks
Efficient Retrieval
Text Classification
Similarity Detection
Text Clustering
Retrieval-Augmented Generation (Rag)
Tags
Text Embedding
Natural Language Processing
Multilingual Support
Semantic Analysis
Contextual Understanding
Efficient Retrieval
Text Classification
Similarity Detection
API Integration
High-Dimensional Vectors
Usage & Integration
Pricing
freemium
Pricing details available on the Gemini API documentation.
API Access
Available
Screenshots & Images
Primary Screenshot

Additional Images













