HumanOmni
by HumanMLLMHumanOmni is a multimodal large model that integrates visual and auditory modalities to comprehensively understand human behavior, emotions, and interactions.
What is HumanOmni?
HumanOmni is a multimodal large model focused on human-centric scenarios, integrating visual and auditory modalities. It processes video, audio, or a combination of both to comprehensively understand human behavior, emotions, and interactions. The model is pre-trained on over 2.4 million video clips and 14 million instructions, employing a dynamic weight adjustment mechanism to flexibly fuse visual and auditory information based on different scenarios. HumanOmni excels in emotion recognition, facial description, and speech recognition, making it suitable for various applications such as movie analysis, close-up video interpretation, and real-time video understanding.
Key Features of HumanOmni
- Multimodal Fusion: HumanOmni can simultaneously process visual (video), auditory (audio), and textual information, fusing features from different modalities through an instruction-driven dynamic weight adjustment mechanism to achieve comprehensive understanding of complex scenarios.
- Human-Centric Scenario Understanding: The model processes face-related, body-related, and interaction-related scenarios through three specialized branches, adaptively adjusting the weights of each branch based on user instructions to meet different task requirements.
- Emotion Recognition and Facial Expression Description: HumanOmni excels in dynamic facial emotion recognition and facial expression description tasks, surpassing existing video-language multimodal models.
- Action Understanding: Through the body-related branch, the model can effectively understand human actions, making it suitable for action recognition and analysis tasks.
- Speech Recognition and Understanding: In speech recognition tasks, HumanOmni uses the audio processing module (e.g., Whisper-large-v3) to achieve efficient understanding of speech, supporting speaker-specific speech recognition.
- Cross-Modal Interaction: The model combines visual and auditory information to more comprehensively understand scenes, making it suitable for tasks such as movie clip analysis, close-up video interpretation, and real-time video understanding.
- Flexible Fine-Tuning Support: Developers can fine-tune HumanOmni's pre-trained parameters to adapt to specific datasets or task requirements.
Technical Principles of HumanOmni
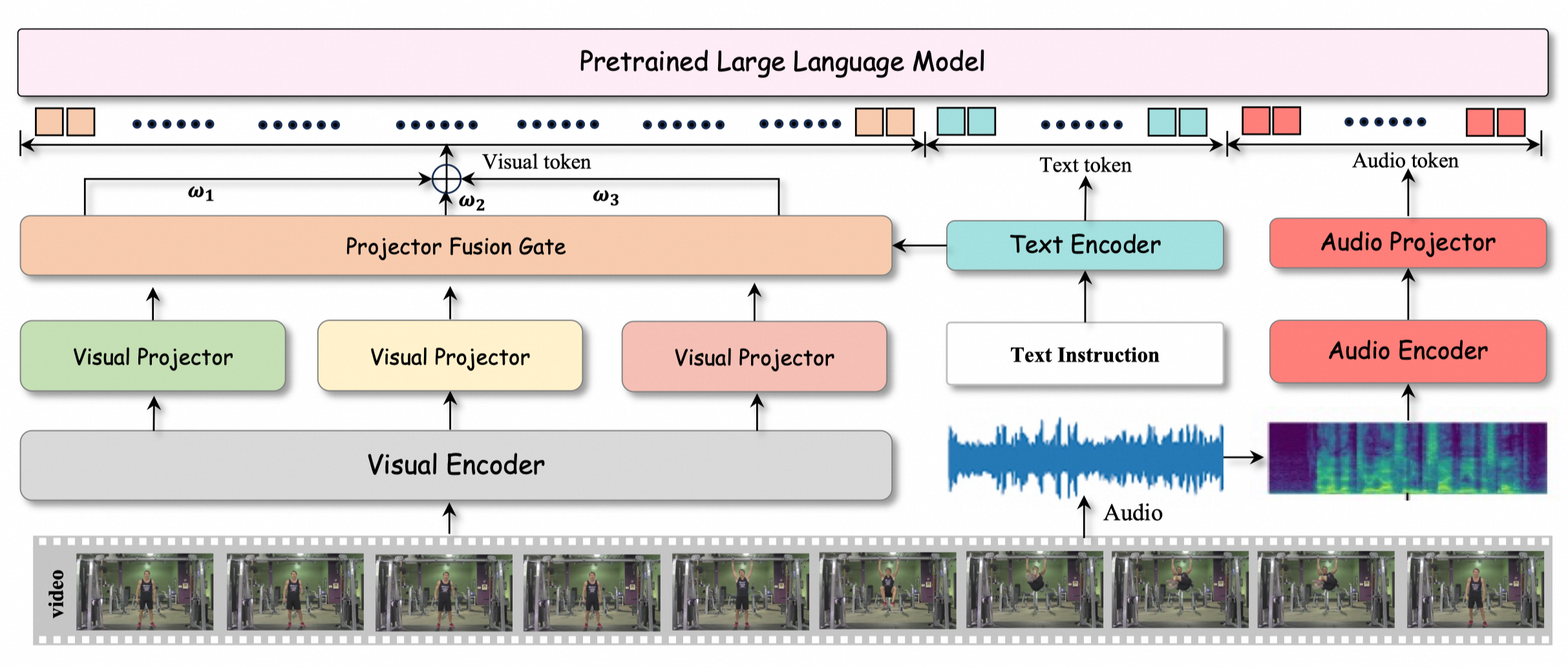
- Multimodal Fusion Architecture: HumanOmni achieves comprehensive understanding of complex scenarios by fusing visual, auditory, and textual modalities. In the visual part, the model designs three branches: face-related, body-related, and interaction-related, capturing features of facial expressions, body movements, and environmental interactions. The instruction-driven fusion module dynamically adjusts weights, adaptively selecting the most suitable visual features for the task based on user instructions.
- Dynamic Weight Adjustment Mechanism: HumanOmni introduces an instruction-driven feature fusion mechanism. BERT encodes user instructions to generate weights, dynamically adjusting the feature weights of different branches. In emotion recognition tasks, the model focuses more on the face-related branch; in interaction scenarios, it prioritizes the interaction-related branch.
- Auditory and Visual Collaborative Processing: In the auditory aspect, HumanOmni uses the Whisper-large-v3 audio preprocessor and encoder to process audio data, mapping it to the text domain through MLP2xGeLU. Visual and auditory features are combined in a unified representation space and further processed by the large language model decoder.
- Multi-Stage Training Strategy: HumanOmni's training is divided into three stages:
- Stage 1: Builds visual capabilities, updating the visual mapper and instruction fusion module parameters.
- Stage 2: Develops auditory capabilities, updating only the audio mapper parameters.
- Stage 3: Integrates cross-modal interaction, enhancing the model's ability to process multimodal information.
- Data-Driven Optimization: HumanOmni is pre-trained on over 2.4 million human-centric video clips and 14 million instruction data, covering tasks such as emotion recognition, facial description, and speaker-specific speech recognition, making the model excel in various scenarios.
Project Addresses of HumanOmni
- Github Repository: https://github.com/HumanMLLM/HumanOmni
- HuggingFace Model Library: https://huggingface.co/StarJiaxing/HumanOmni-7B
- arXiv Technical Paper: https://arxiv.org/pdf/2501.15111
Application Scenarios of HumanOmni
- Film and Entertainment: HumanOmni can be used in film production, such as virtual character animation generation, virtual hosts, and music video creation.
- Education and Training: In education, HumanOmni can create virtual teachers or simulation training videos, assisting in language learning and vocational skill training.
- Advertising and Marketing: HumanOmni can generate personalized advertisements and brand promotion videos, analyzing human emotions and actions to provide more engaging content and enhance user engagement.
- Social Media and Content Creation: HumanOmni helps creators quickly generate high-quality short videos, supporting interactive video creation to increase content interest and appeal.
Model Capabilities
Model Type
multimodal
Supported Tasks
Emotion Recognition
Facial Description
Speech Recognition
Action Understanding
Cross-Modal Interaction
Tags
Multimodal
Human-Centric
Emotion Recognition
Speech Recognition
Video Analysis
Audio Processing
AI Models
Behavior Understanding
Interaction Analysis
Real-Time Processing
Usage & Integration
License
Open Source
Screenshots & Images
Additional Images