Loopy
by ByteDanceLoopy is an audio-driven AI video generation model by ByteDance that animates static photos, synchronizing facial expressions and head movements with given audio files to create realistic dynamic videos.
What is Loopy?
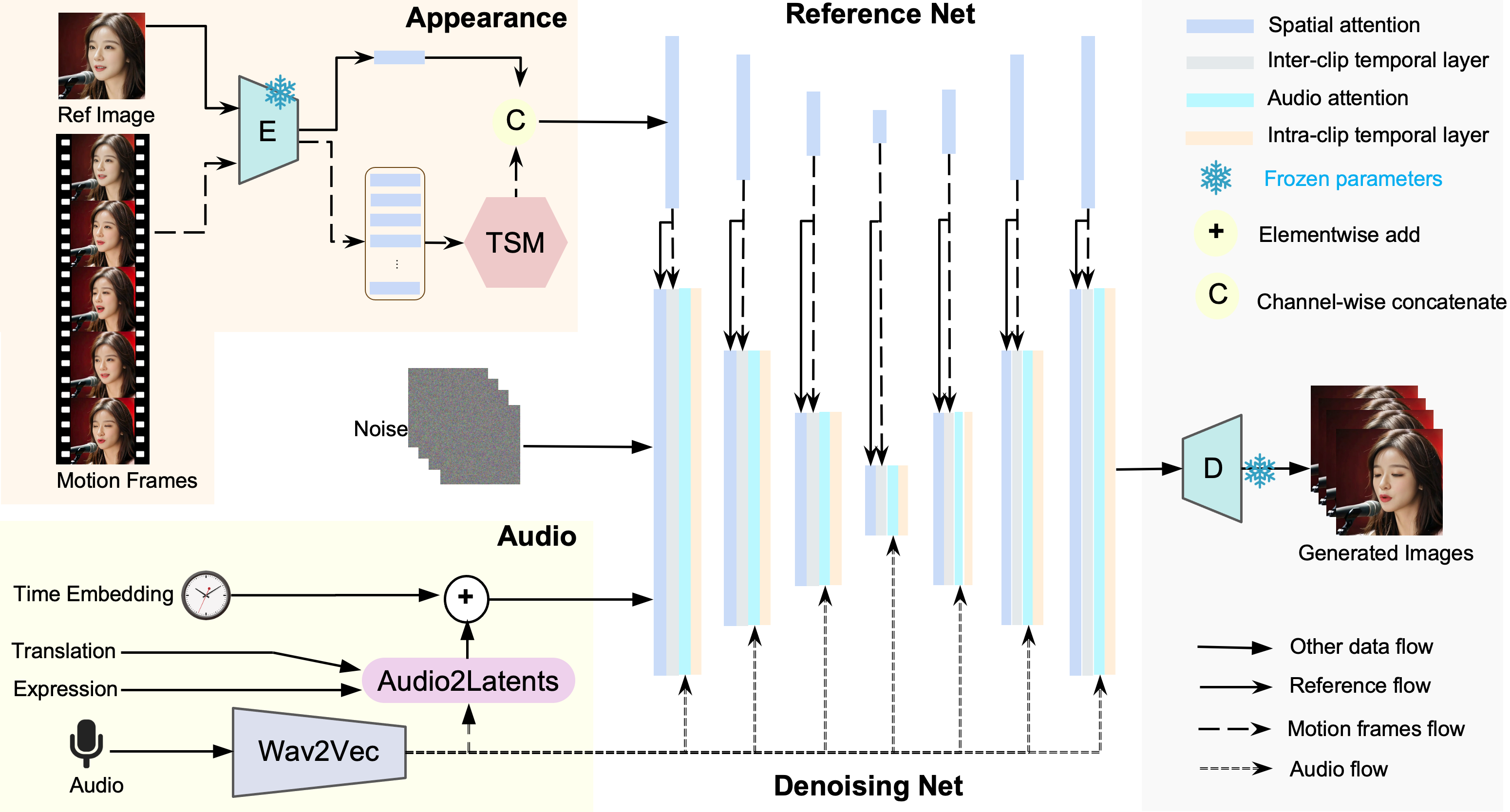
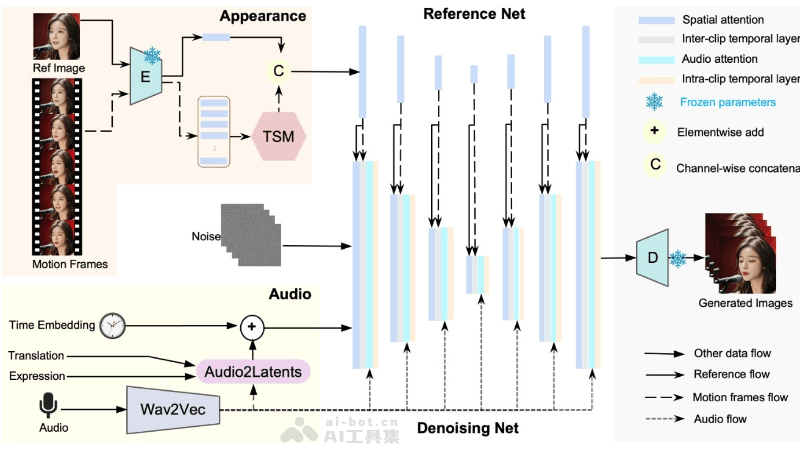
Loopy is an audio-driven AI video generation model developed by ByteDance. It allows users to animate static photos, where the characters in the photos synchronize their facial expressions and head movements with the provided audio file, resulting in realistic dynamic videos. Loopy is based on advanced diffusion model technology, capturing and learning long-term motion information without the need for additional spatial signals or conditions, making it suitable for various scenarios such as entertainment and education.
Key Features of Loopy
- Audio-Driven: Loopy uses audio files as input to automatically generate dynamic videos synchronized with the audio.
- Facial Motion Generation: It generates natural movements of facial features such as the mouth, eyebrows, and eyes, making the static image appear as if it is speaking.
- No Additional Conditions Needed: Unlike some similar technologies that require additional spatial signals or conditions, Loopy does not need auxiliary information and can independently generate videos.
- Long-Term Motion Information Capture: Loopy has the ability to process long-term motion information, resulting in more natural and fluid movements.
- Diverse Output: It supports generating diverse motion effects, producing corresponding facial expressions and head movements based on the characteristics of the input audio, such as emotion and rhythm.
Technical Principles of Loopy
- Audio-Driven Model: The core of Loopy is an audio-driven video generation model that generates dynamic videos synchronized with the input audio signal.
- Diffusion Model: Loopy uses diffusion model technology, which generates data by gradually introducing noise and learning the reverse process.
- Temporal Module: Loopy has designed temporal modules that work across and within segments, allowing the model to understand and utilize long-term motion information to generate more natural and coherent movements.
- Audio-to-Latent Space Conversion: Loopy converts audio signals into latent representations that drive facial movements through an audio-to-latent space module.
- Motion Generation: Based on features extracted from the audio and long-term motion information, Loopy generates corresponding facial movements, such as dynamic changes in the mouth, eyebrows, and eyes.
Application Scenarios of Loopy
- Social Media and Entertainment: Adding dynamic effects to photos or videos on social media to increase interactivity and entertainment value.
- Film and Video Production: Creating special effects, such as "reviving" historical figures.
- Game Development: Generating more natural and realistic facial expressions and movements for non-player characters (NPCs) in games.
- VR and AR: Creating more realistic and immersive virtual characters in VR or AR experiences.
- Education and Training: Producing educational videos, simulating speeches by historical figures, or recreating scientific experiments.
- Advertising and Marketing: Creating engaging advertising content to enhance the appeal and memorability of ads.
Model Capabilities
Model Type
multimodal
Supported Tasks
Video Generation
Facial Animation
Audio Synchronization
Tags
AI Video Generation
Audio-Driven
ByteDance
Diffusion Model
Facial Animation
Video Synthesis
Entertainment
Education
Multimedia
AI Research
Usage & Integration
Pricing
free
Screenshots & Images
Primary Screenshot

Additional Images
Stats
104
Views
0
Favorites









