MinMo
by Alibaba Tongyi LabWhat is MinMo?
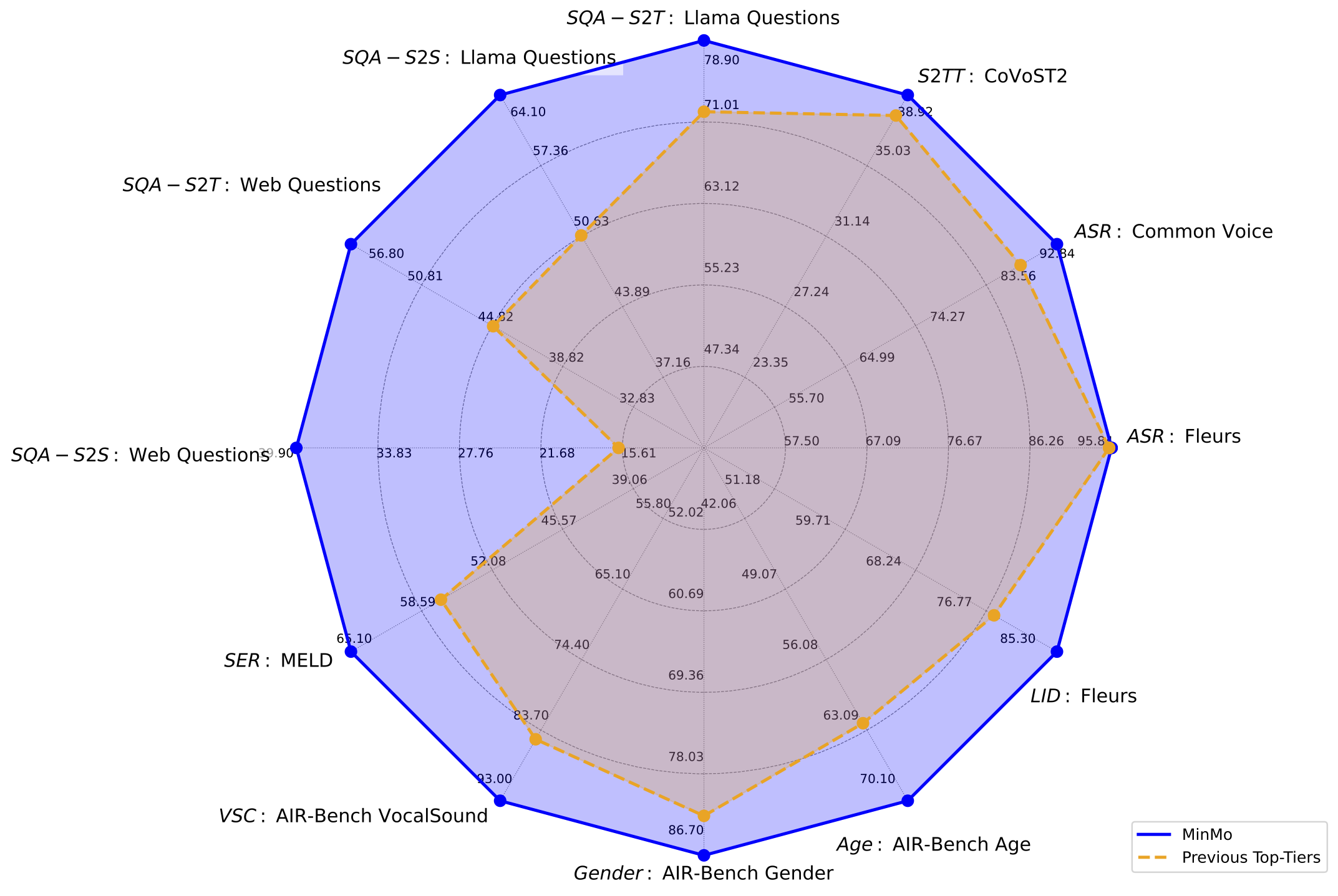
MinMo is a multimodal large model developed by the FunAudioLLM team at Alibaba Tongyi Lab, focusing on achieving seamless voice interaction. With approximately 8 billion parameters, MinMo is trained in multiple stages on 1.4 million hours of diverse voice data and a wide range of voice tasks. It supports controlling the emotion, dialect, and speaking style of generated audio based on user instructions, as well as mimicking specific timbres, with a generation efficiency of over 90%. MinMo supports full-duplex voice interaction, with a voice-to-text latency of about 100 milliseconds, full-duplex latency theoretically around 600 milliseconds, and practically around 800 milliseconds, enabling simultaneous bidirectional communication between the user and the system, making multi-turn conversations smoother.
Main Features of MinMo
- Real-time Voice Conversation: Can engage in real-time, natural, and smooth voice conversations with users, understanding voice commands and generating corresponding voice responses.
- Multilingual Support: Supports multilingual voice recognition and translation, enabling smooth communication in various language environments.
- Emotion Expression: Generates voice with specific emotions (such as happiness, sadness, surprise, etc.) based on user instructions.
- Dialect and Speaking Style: Supports generating voice in specific dialects (such as Sichuanese, Cantonese, etc.) and specific speaking styles (such as fast, slow, etc.).
- Timbre Imitation: Mimics specific timbres, making voice interactions more personalized and expressive.
- Full-duplex Interaction: Supports simultaneous speaking and listening by the user and the system, enabling more natural and efficient multi-turn conversations, with a voice-to-text latency of about 100 milliseconds, full-duplex latency theoretically around 600 milliseconds, and practically around 800 milliseconds.
Technical Principles of MinMo
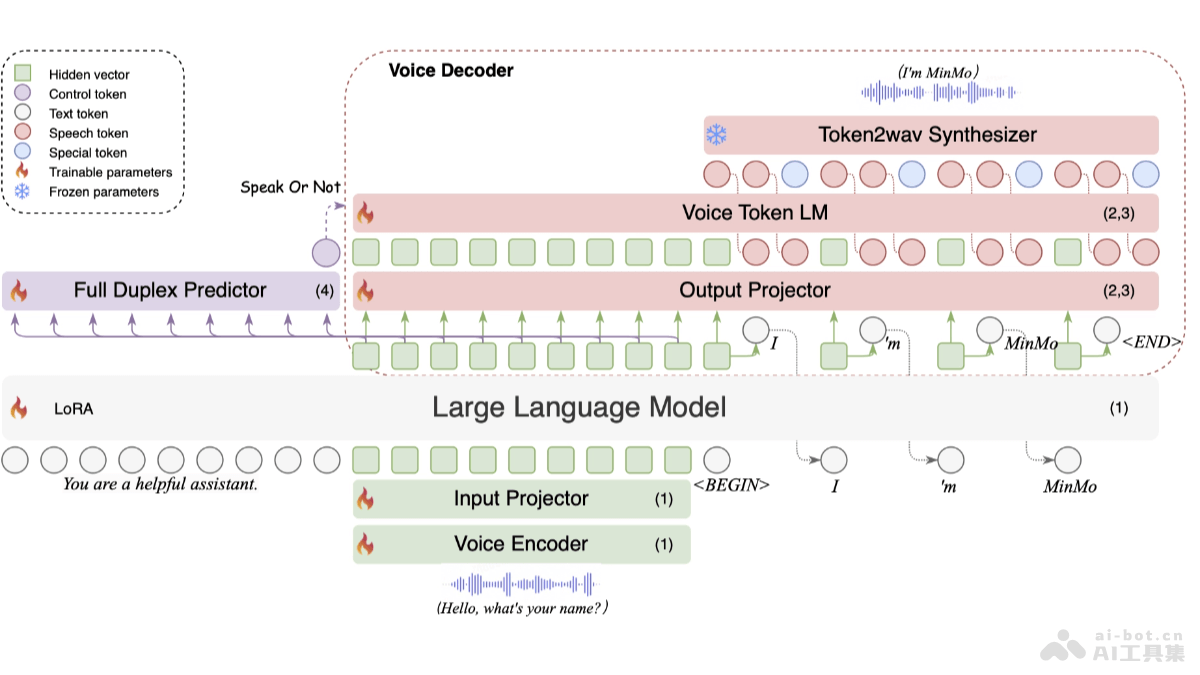
- Multimodal Fusion Architecture:
- Voice Encoder: Based on the pre-trained SenseVoice-large encoder module, providing powerful voice understanding capabilities, supporting multilingual voice recognition, emotion recognition, and audio event detection.
- Input Projector: Consists of two layers of Transformer and one layer of CNN, used for dimension alignment and downsampling.
- Large Language Model: Uses the pre-trained Qwen2.5-7B-instruct model, known for its excellent performance in multiple benchmarks.
- Output Projector: A single-layer linear module used for dimension alignment.
- Voice Token Language Model: Uses the pre-trained CosyVoice 2 LM module for autoregressive generation of voice tokens.
- Token2wav Synthesizer: Converts voice tokens into mel spectrograms, then into waveforms, supporting real-time audio synthesis.
- Full-duplex Predictor: A single-layer Transformer and linear softmax output layer, used for real-time prediction of whether to continue system response or pause for user input.
- Multi-stage Training Strategy:
- Voice-to-text Alignment: Trains the model to learn the mapping relationship between voice and text based on a large amount of voice data and corresponding text annotations, enabling accurate conversion of voice to text, laying the foundation for subsequent text understanding and generation.
- Text-to-voice Alignment: Enables the model to learn how to convert text into voice, generating natural and smooth voice expressions while maintaining the semantic information and emotional color of the text.
- Voice-to-voice Alignment: Further enhances the model's ability to understand and generate voice, enabling direct interaction at the voice level, better handling voice features such as rhythm and intonation.
- Full-duplex Interaction Alignment: Simulates real full-duplex interaction scenarios, training the model to accurately perform voice recognition and generation while simultaneously receiving and sending voice signals, optimizing the model's performance in complex interaction environments.
Project Address of MinMo
- Project Website: https://funaudiollm.github.io/minmo/
- arXiv Technical Paper: https://arxiv.org/pdf/2501.06282
Application Scenarios of MinMo
- Intelligent Customer Service: Provides 24/7 multilingual voice support, real-time interaction to answer customer questions, personalized services based on emotion recognition, and full-duplex dialogue to improve efficiency.
- Intelligent Assistant: Controls smart home devices, manages schedules, queries information, recommends personalized content, enhancing life convenience and information acquisition efficiency.
- Education: Assists in language learning, interactive teaching to increase engagement, provides personalized plans based on learning progress, and offers emotional support to encourage students.
- Healthcare: Remote medical consultation, health monitoring reminders, rehabilitation training guidance, emotional support and counseling, improving the accessibility of medical services and patient experience.
- Intelligent Driving: Voice control of vehicle systems, provides real-time traffic information, emergency situation guidance, and full-duplex dialogue to enhance driving safety and convenience.
Model Capabilities
Usage & Integration
Screenshots & Images