
Parler-TTS
by Hugging FaceParler-TTS is an open-source text-to-speech model by Hugging Face that generates high-quality, natural-sounding speech by mimicking specific speaker styles based on input prompts.
What is Parler-TTS?
Parler-TTS is an open-source text-to-speech (TTS) model developed by Hugging Face. It generates high-quality, natural-sounding speech by mimicking specific speaker styles (gender, pitch, speaking style, etc.) based on input prompts. The model is fully open-source, including datasets, preprocessing, training code, and weights, promoting innovation in high-quality, controllable TTS models.
Key Features
- High-Quality Voice Generation: Produces natural-sounding speech based on text input, mimicking different speaking styles.
- Diverse Voice Output: Allows control over voice style, including age, emotion, speed, and environment.
- Open-Source Architecture: Based on MusicGen, integrating text encoders, decoders, and audio codecs.
- Custom Training and Fine-Tuning: Users can train the model with their own datasets for specific styles or accents.
- Ethics and Privacy Protection: Avoids voice cloning techniques, ensuring ethical and compliant technology.
Technical Architecture
Parler-TTS's architecture is based on MusicGen, with key components:
- Text Encoder: Maps text descriptions to hidden state representations using a frozen Flan-T5 model.
- Parler-TTS Decoder: Autoregressively generates audio tokens based on the encoder's hidden states.
- Audio Codec: Converts audio tokens into audible waveforms using the DAC model.
- Architecture Improvements: Integrates text descriptions into the decoder's cross-attention layers for better voice generation.
How to Use
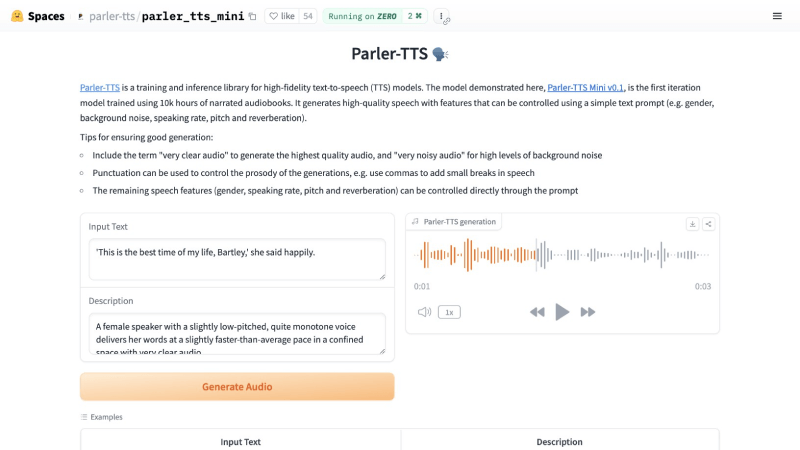
- Visit the Parler-TTS Hugging Face Demo.
- Enter the text you want to transcribe in the "Input Text" field.
- Describe the desired voice in the "Description" field.
- Click "Generate Audio" to produce the voice.
Use Cases
- Content Creation: Generate voiceovers for videos, podcasts, or audiobooks.
- Accessibility: Provide speech synthesis for visually impaired users.
- Custom Applications: Develop custom TTS solutions for specific industries or languages.
Model Capabilities
Model Type
Text-to-Speech
Supported Tasks
Speech Synthesis
Voice Style Mimicking
Custom Voice Generation
Tags
Text-to-Speech
Open Source
AI Model
Natural Language Processing
Voice Generation
Customizable
High-Quality Audio
Developer Tools
Ethical AI
Speech Synthesis
Usage & Integration
Pricing
free
License
Open Source
Open Source
Screenshots & Images
Primary Screenshot
Additional Images
Stats
192
Views
0
Favorites









