SignLLM
What is SignLLM?
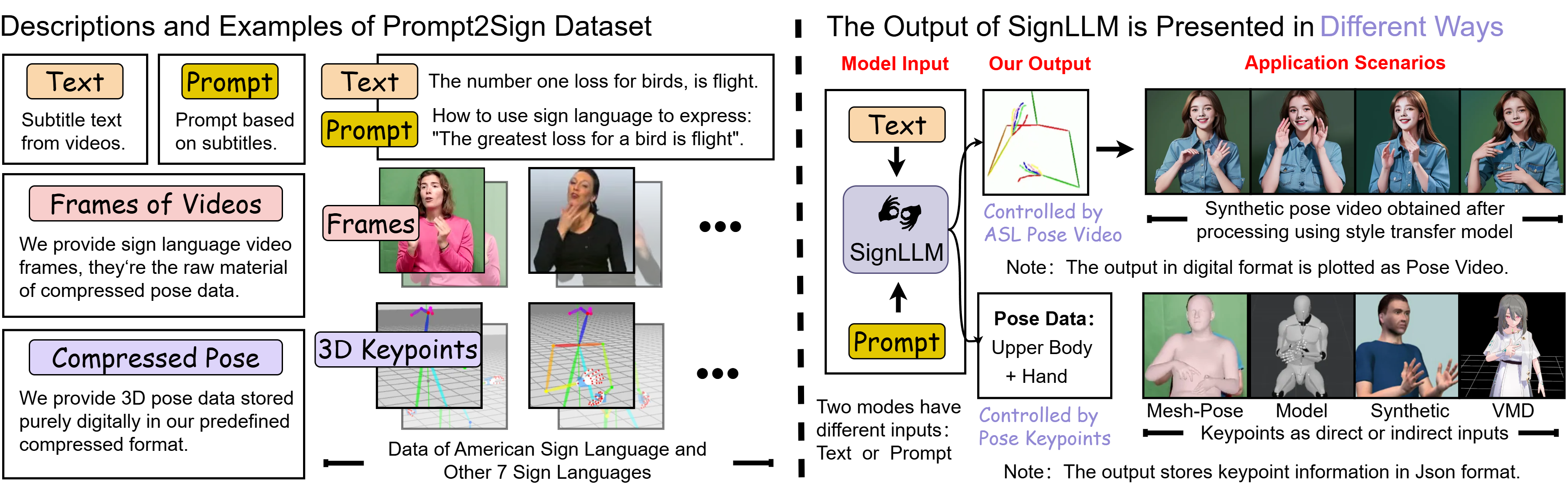
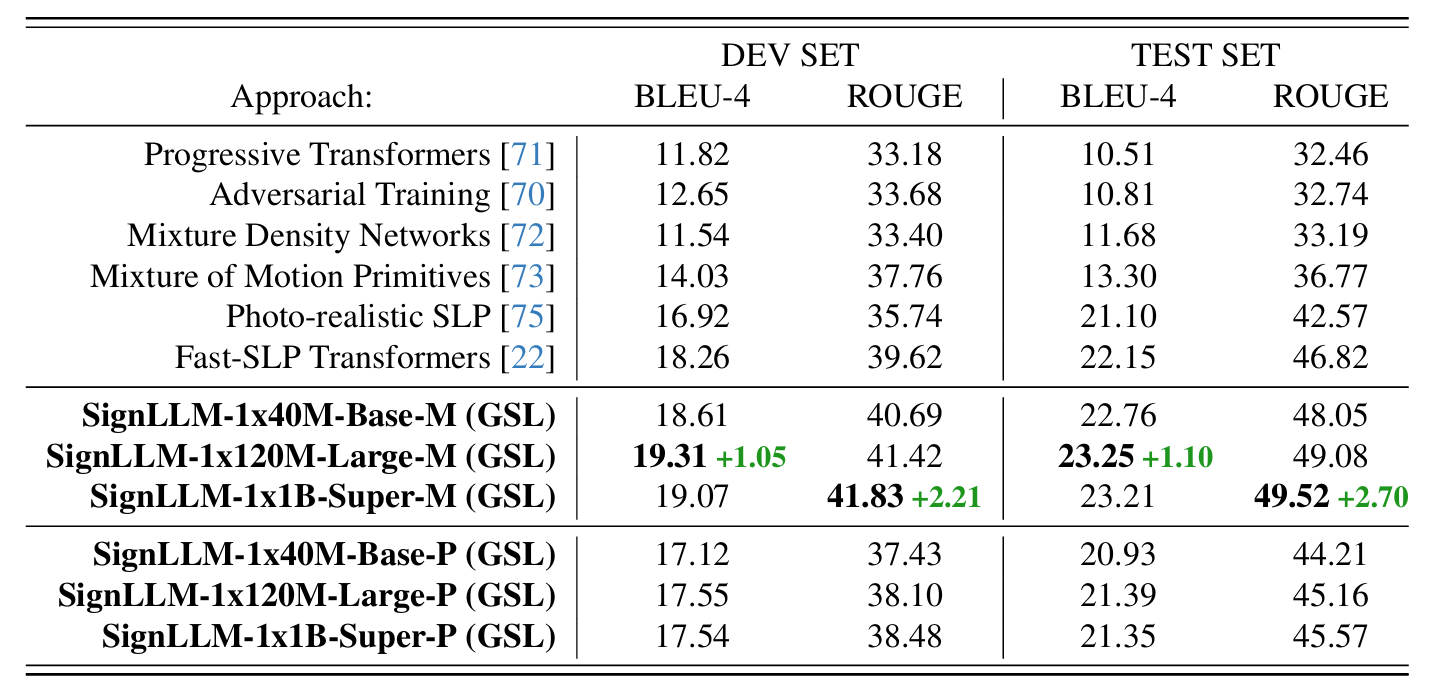
SignLLM is an innovative multilingual sign language generation model that converts text input into corresponding sign language videos. It is the world's first model to support multiple sign languages, including American Sign Language (ASL), German Sign Language (GSL), Argentine Sign Language (LSA), Korean Sign Language (KSL), and more. The model is developed based on the Prompt2Sign dataset, utilizing automated techniques to collect and process sign language videos from the web. It incorporates new loss functions and reinforcement learning modules to achieve efficient data extraction and model training.
Key Features of SignLLM
- Sign Language Video Generation: Converts input text into natural and fluent sign language gesture videos, supporting multiple languages.
- Multilingual Support: Supports eight sign languages, covering different countries and regions.
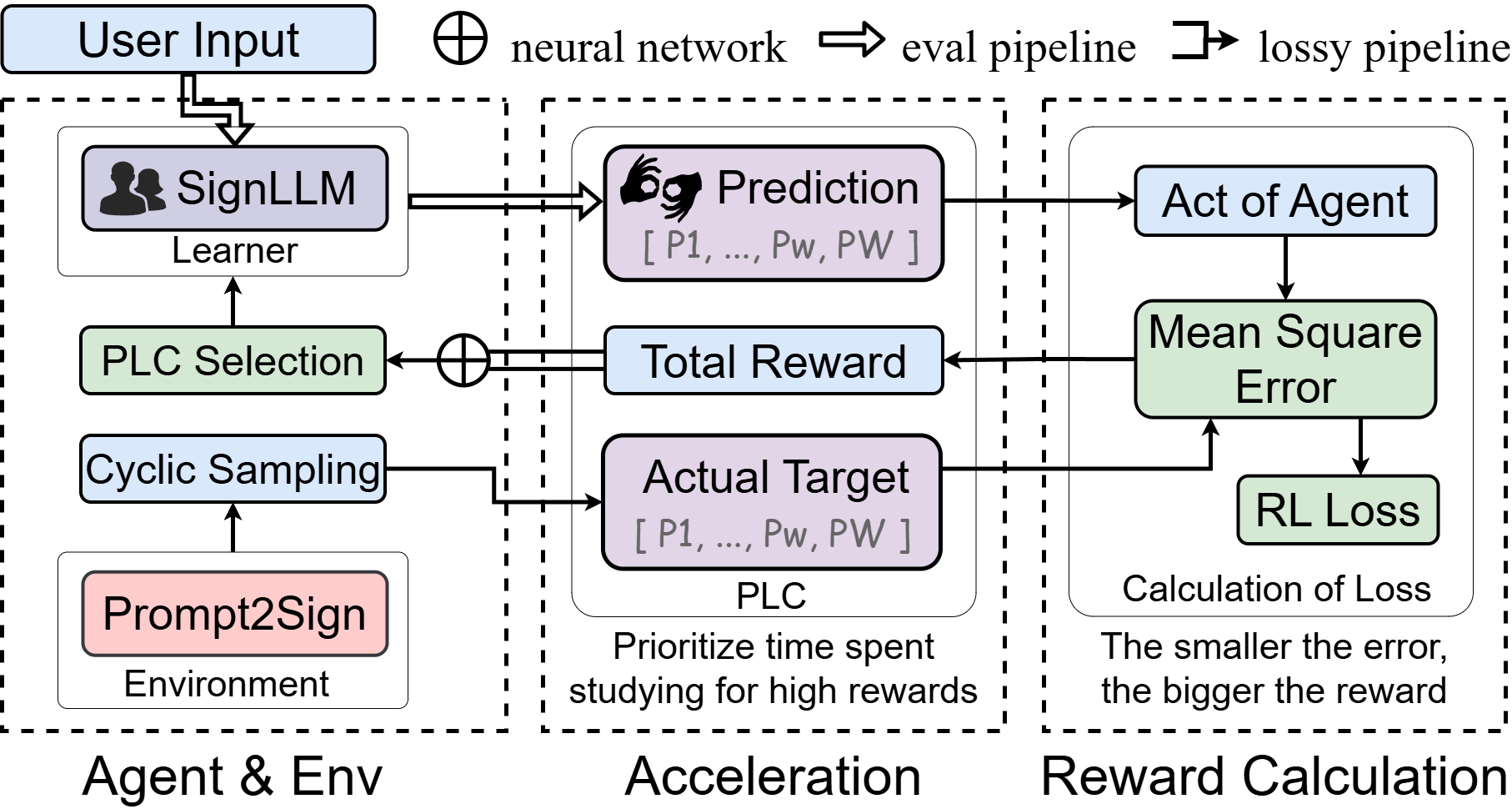
- Efficient Training and Optimization: Accelerates the training process through reinforcement learning modules, improving data sampling quality.
- Style Transfer and Fine-Tuning: Transforms the model's output into realistic sign language videos, closely resembling real human appearances.
- Education and Translation Support: Can be used for sign language teaching, sign language translation, and providing communication support for the deaf community.
Technical Principles of SignLLM
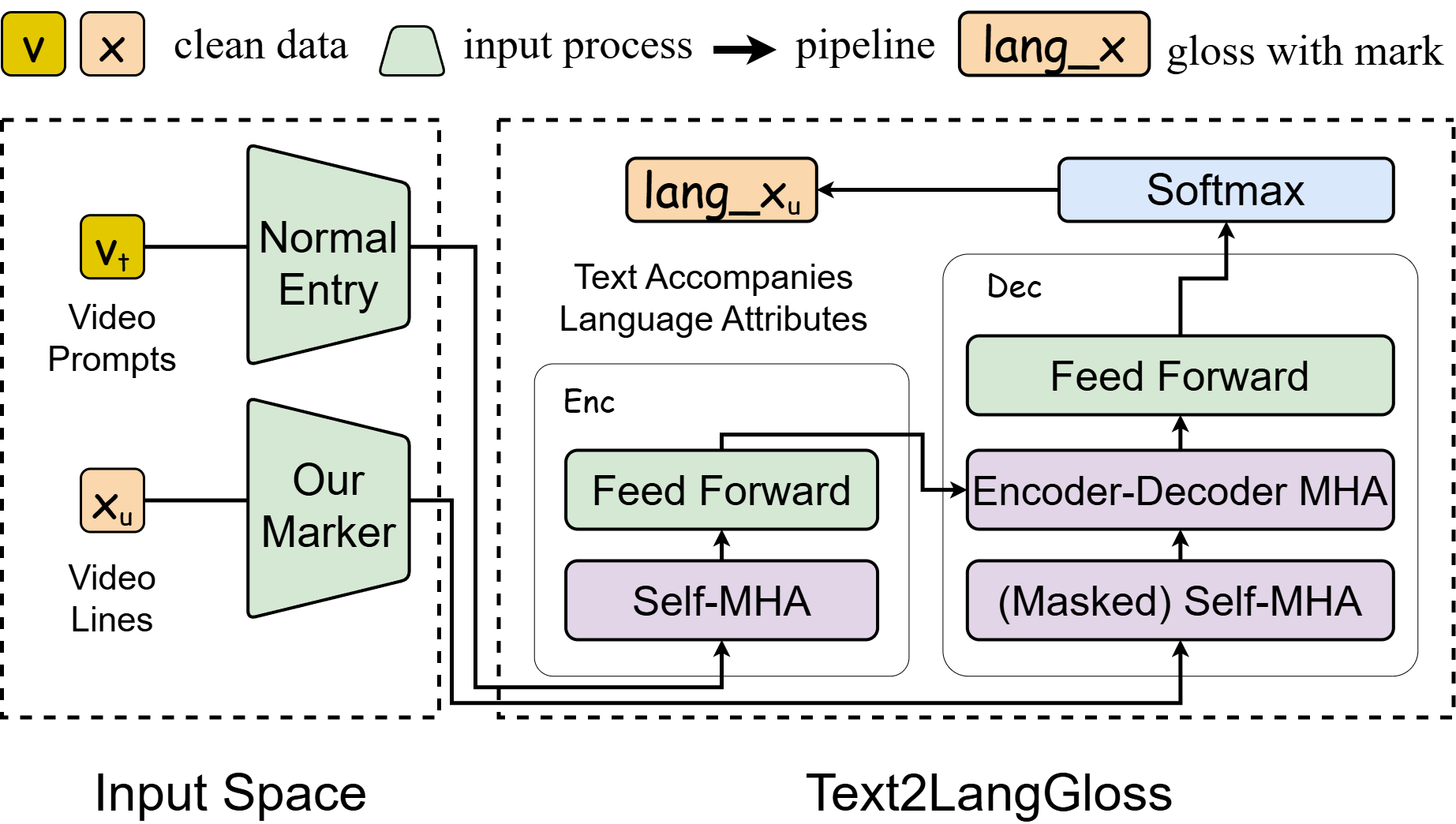
- Discretization and Hierarchical Representation: SignLLM achieves discretization and hierarchical representation of sign language videos through two key modules. First, the Vector Quantized Visual Sign Language (VQ-Sign) module decomposes sign language videos into a series of discrete character-level tokens, similar to characters in language. Then, the Codebook Reconstruction and Alignment (CRA) module combines these character-level tokens into vocabulary-level tokens, forming a hierarchical structure of sign language sentences.
- Self-Supervised Learning and Context Prediction: The VQ-Sign module performs self-supervised learning through context prediction tasks, rather than traditional video reconstruction methods. This allows it to capture the temporal dependencies and semantic relationships of sign language videos without reconstructing high-dimensional video data.
- Sign-Text Alignment: To further improve the semantic compatibility between sign language tokens and text tokens, SignLLM uses the Maximum Mean Discrepancy (MMD) loss function to align the embedding space of sign language tokens with that of text tokens.
- Integration with LLM: SignLLM combines the generated sign language sentences with a frozen LLM, guiding the LLM to generate translations in the target language through text prompts. This leverages the powerful translation capabilities of LLMs to achieve efficient sign language-to-text translation.
- Training and Inference: SignLLM's training is divided into two stages: pre-training and fine-tuning. The pre-training stage includes context prediction tasks and codebook alignment, while the fine-tuning stage further optimizes model performance.
Project Links for SignLLM
- Project Website: https://signllm.github.io/
- Github Repository: https://github.com/SignLLM
- arXiv Technical Paper: https://arxiv.org/pdf/2405.10718
Application Scenarios of SignLLM
- Education: SignLLM can serve as a virtual sign language teacher, converting text into sign language gesture videos to help students learn sign language more intuitively and accelerate the learning process.
- Healthcare: In medical environments such as hospitals, SignLLM can convert doctors' speech or text into sign language in real-time, helping hearing-impaired patients describe symptoms more accurately and understand medical instructions, improving their healthcare experience.
- Legal and Public Services: In courtrooms or legal consultations, SignLLM can provide accurate sign language translation, ensuring fair communication opportunities for hearing-impaired individuals in legal matters. Additionally, it can offer instant sign language translation in public services or customer service, making it convenient for the hearing-impaired community.
- Entertainment and Media: SignLLM can provide real-time sign language translation for movies, TV shows, or online videos, enriching the cultural life of the hearing-impaired community.
- Daily Life: Individual users can use SignLLM for daily communication, such as chatting with hearing-impaired friends or communicating in quiet environments.
Model Capabilities
Usage & Integration
Screenshots & Images
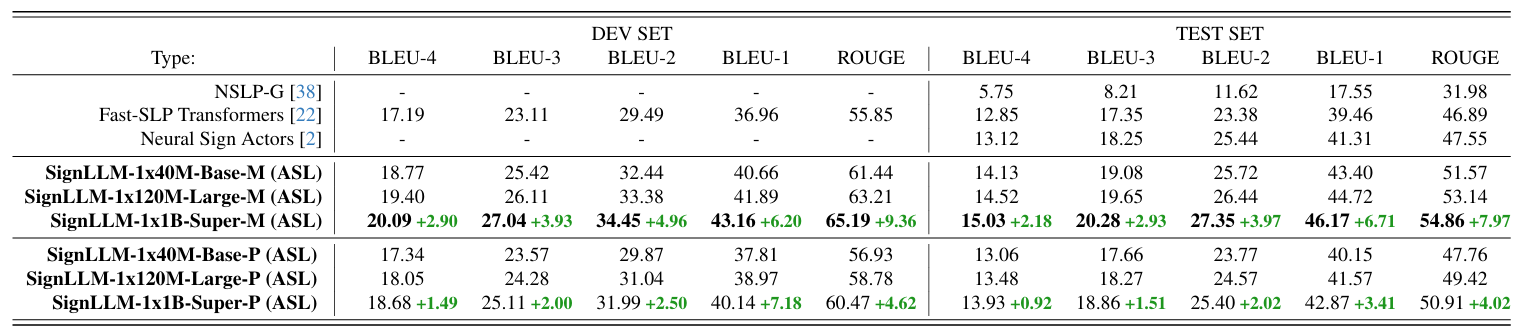

Stats
Community & Support
Similar Models
The AI discovery platform. Deep analysis, honest comparisons, and real metrics to help you find the best AI for any task.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









