VLM-R1
by Om AI LabVLM-R1 is a visual language model that uses reinforcement learning to precisely locate target objects in images based on natural language instructions.
What is VLM-R1?
VLM-R1 is a visual language model developed by Om AI Lab, designed to accurately locate target objects in images based on natural language instructions. It leverages reinforcement learning and the Qwen2.5-VL architecture to excel in complex scenes and cross-domain data.
Key Features
- Referential Expression Comprehension (REC): Parses natural language instructions to locate specific objects in images.
- Joint Image and Text Processing: Simultaneously processes images and text for accurate analysis.
- Reinforcement Learning Optimization: Uses GRPO technology for enhanced generalization and stability.
- Efficient Training and Inference: Supports single GPU training for large-scale models.
- Multimodal Reasoning and Knowledge Generation: Identifies image content, performs logical reasoning, and generates text expressions.
Technical Details
- GRPO Reinforcement Learning: Enables self-exploration in complex scenes without extensive annotated data.
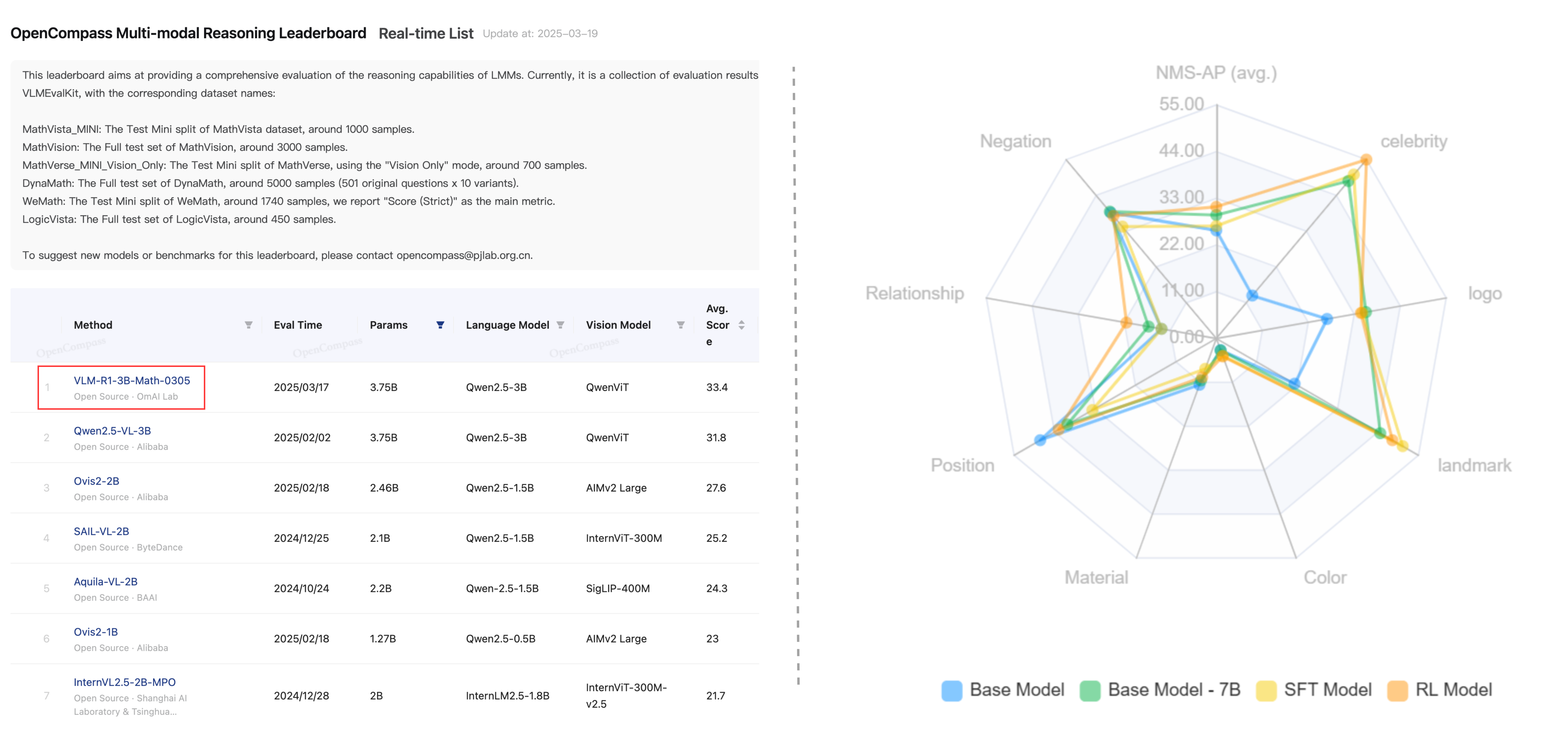
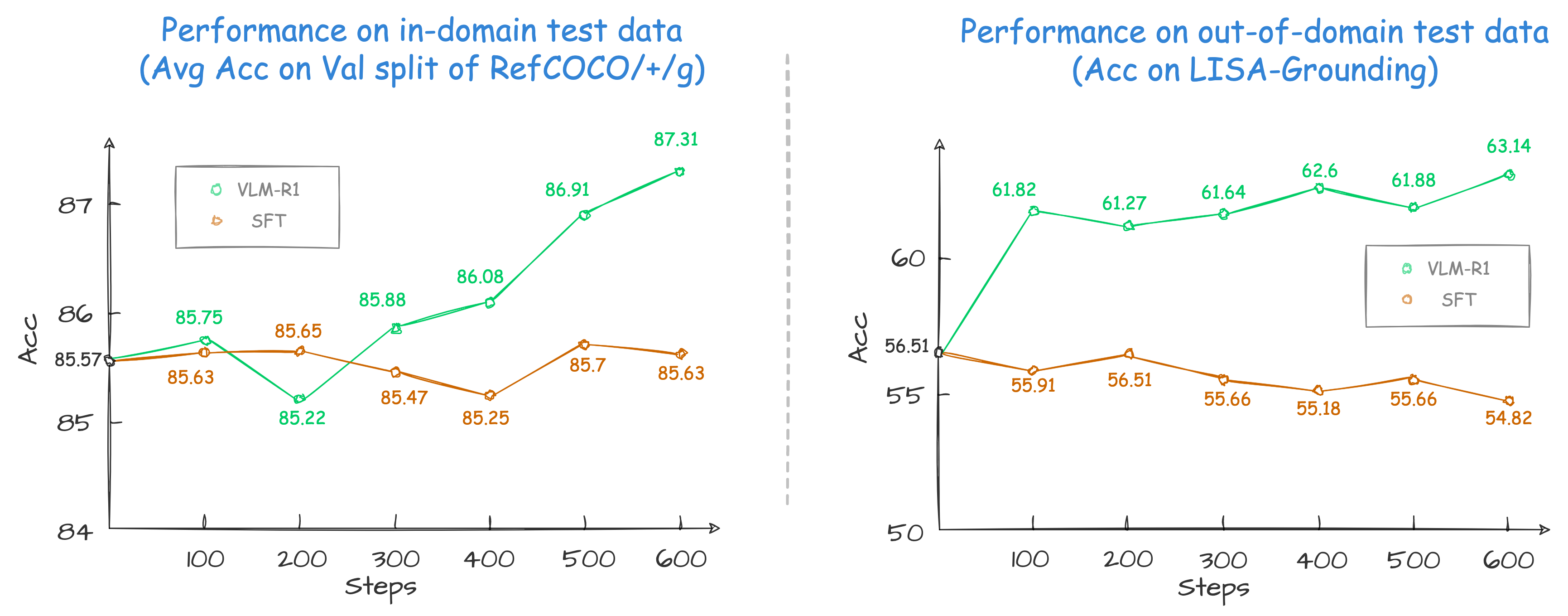
- Enhanced Generalization: Outperforms traditional supervised fine-tuning methods in out-of-domain tests.
- Qwen2.5-VL Architecture: Provides a stable and efficient foundation for the model.
Use Cases
- Smart Assistants: Parses user instructions and provides precise feedback based on image data.
- Accessibility Assistance: Helps visually impaired individuals identify hazards in their environment.
- Autonomous Driving: Enhances safety by identifying complex traffic scenes.
- Medical Imaging Analysis: Provides accurate diagnostic recommendations for rare diseases.
- Smart Home and IoT: Combines camera and sensor data to identify home events.
Getting Started
Visit the GitHub repository for complete training and evaluation processes. The model is open source and available under the Apache-2.0 license.
Model Capabilities
Model Type
multimodal
Supported Tasks
Referential Expression Comprehension
Joint Image And Text Processing
Multimodal Reasoning
Object Localization
Knowledge Generation
Tags
Visual Language Model
Reinforcement Learning
Natural Language Processing
Computer Vision
Multimodal AI
Object Detection
Image Analysis
AI Research
Open Source
Deep Learning
Usage & Integration
Pricing
free
License
Open Source
Apache-2.0
Screenshots & Images
Primary Screenshot
Additional Images
Stats
114
Views
0
Favorites









