The State of LLMs: Benchmark Landscape Report Q2 2026
Mapping the latest language models across intelligence, cost, and speed — from GPT-5.5 to DeepSeek V4
Executive Summary
A comprehensive landscape analysis of the LLM market as of May 2026, mapping models across intelligence score, cost efficiency, output speed, and latency. Based on data from the Artificial Analysis leaderboard, LMSYS Arena, and BestAI evaluation tasks. The market has evolved dramatically: GPT-5.5 leads on raw intelligence, but Chinese models (Qwen3.7, DeepSeek V4, MiMo-V2.5) deliver near-premium quality at a fraction of the cost. This report covers the top 20 models, pricing analysis, market positioning, and recommendations for different use cases.
Key Findings
GPT-5.5 leads on raw intelligence (score 60) but at $4.35/M tokens — Claude Opus 4.7 (score 57) and Qwen3.7 Max (score 57) are neck-and-neck at lower prices
Chinese models dominate cost efficiency: MiMo-V2.5-Pro (score 54) costs just $0.18/M tokens — delivering 90% of GPT-5.5 intelligence at 4% of the cost
DeepSeek V4 Flash at $0.06/M tokens achieves score 47 — making premium-level AI essentially free for high-volume applications
Output speed varies 18x: Mercury 2 outputs 903 tokens/sec vs Claude Opus 4.7 at 55 tokens/sec — critical for real-time applications
The intelligence gap between top-10 models has compressed to just 13 points (60 vs 47), down from a 20+ point spread a year ago
Open-weights models (Kimi K2.6, MiMo-V2.5-Pro at score 54) now match last year's proprietary frontier models
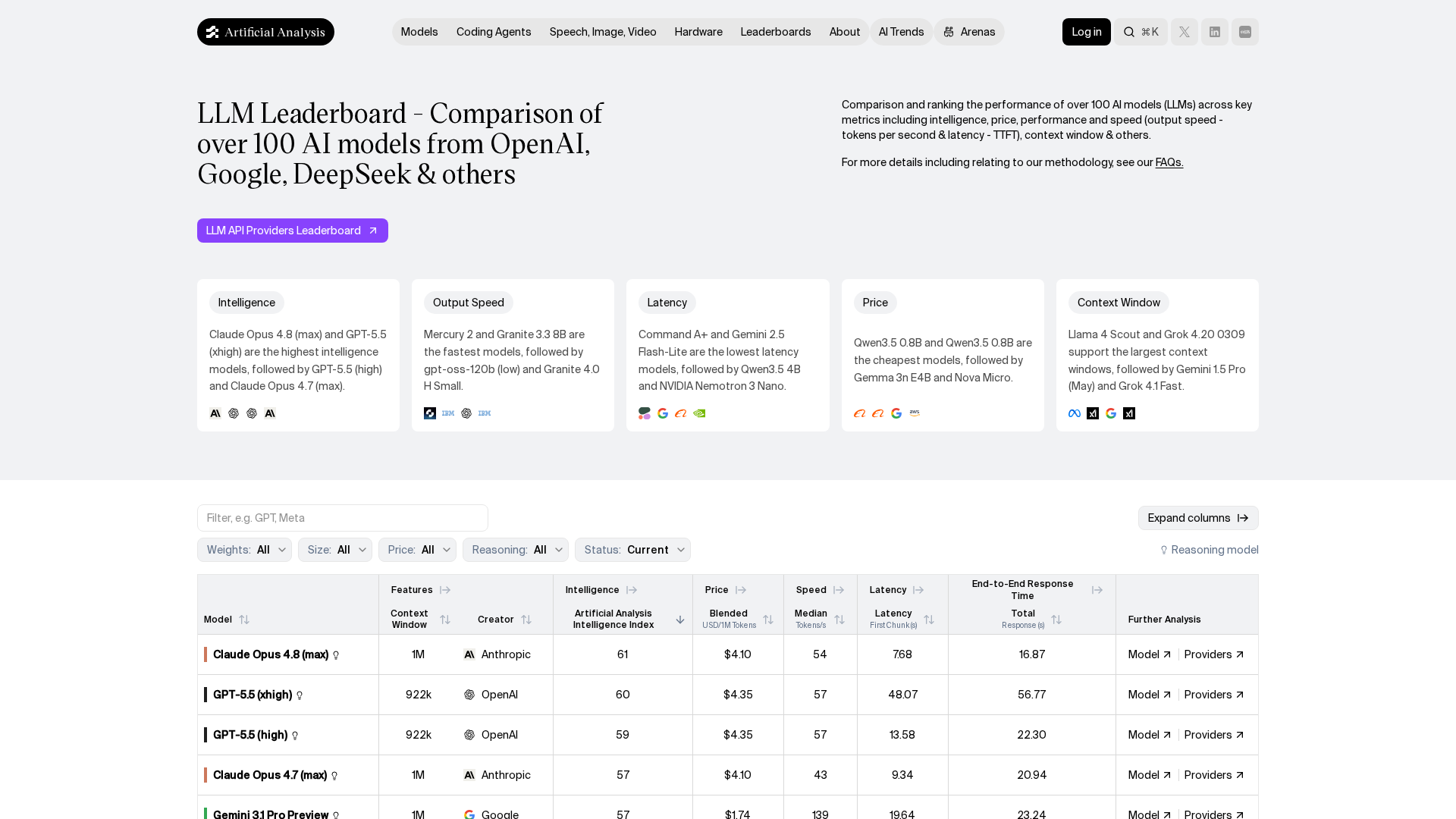
Top Models by Intelligence Score (May 2026)
Scores from the Artificial Analysis Intelligence Index. Price is blended per 1M tokens. Speed is output tokens per second. Data as of May 2026.
| Model | Creator | Score | Price $/M | Speed t/s | Latency (s) |
|---|---|---|---|---|---|
| GPT-5.5 (xhigh) | OpenAI | 60 | $4.35 | 70 | 56.9 |
| GPT-5.5 (high) | OpenAI | 59 | $4.35 | 75 | 22.2 |
| Claude Opus 4.7 (max) | Anthropic | 57 | $4.10 | 55 | 25.6 |
| Gemini 3.1 Pro Preview | 57 | $1.74 | 138 | 30.6 | |
| Qwen3.7 Max | Alibaba | 57 | $1.43 | 211 | 2.5 |
| Gemini 3.5 Flash | 55 | $1.31 | 212 | 15.4 | |
| Kimi K2.6 (reasoning) | Kimi | 54 | $0.70 | 30 | 3.1 |
| MiMo-V2.5-Pro | Xiaomi | 54 | $0.18 | 50 | 3.8 |
| Grok 4.3 (high) | xAI | 53 | $0.64 | 190 | 19.7 |
| Claude Opus 4.7 (non-reasoning) | Anthropic | 52 | $4.10 | 50 | 1.9 |
| Claude Sonnet 4.6 (max) | Anthropic | 52 | $2.46 | 64 | 146.2 |
| DeepSeek V4 Pro (Max) | DeepSeek | 52 | $0.18 | 53 | 1.8 |
| GPT-5.5 (low) | OpenAI | 51 | $4.35 | 74 | 2.0 |
| DeepSeek V4 Pro (High) | DeepSeek | 50 | $0.18 | 53 | 1.9 |
| MiMo-V2.5 | Xiaomi | 49 | $0.06 | 94 | 2.8 |
| GPT-5.4 mini (xhigh) | OpenAI | 49 | $0.65 | 172 | 8.8 |
Head-to-Head Comparison
GPT-5.5
- Highest intelligence score (60)
- Strong across all modalities
- Richest ecosystem (GPT Store, plugins)
- Multiple effort levels (xhigh to low)
- Most expensive at $4.35/M
- Slowest at xhigh (57s latency)
- Diminishing returns vs score-57 models
- Rate limits on highest tiers
Claude Opus 4.7
- Best for coding and agentic workflows
- 1M token context window
- Strong instruction following
- Available in reasoning and non-reasoning modes
- Slowest output speed (55 t/s)
- High latency in max mode (25.6s)
- Premium pricing at $4.10/M
- Fewer multimodal features than GPT-5.5
Qwen3.7 Max
- Matches Claude Opus 4.7 intelligence at 65% lower cost
- Fastest top-tier model (211 t/s)
- Lowest latency among score-57 models (2.5s)
- Strong multilingual (Chinese + English)
- Alibaba ecosystem may concern some enterprises
- Less established developer tooling
- Fewer third-party integrations
- Geopolitical considerations for some organizations
DeepSeek V4 Pro
- Score 52 at just $0.18/M — 24x cheaper than GPT-5.5
- Fast inference (53 t/s)
- Ultra-low latency (1.8s)
- Excellent for high-volume production
- 8-point intelligence gap vs GPT-5.5
- China-based raises compliance concerns
- Less reliable on hardest reasoning tasks
- Smaller context window
Intelligence Scores: The Top Tier Converges
The most striking finding is how compressed the top of the leaderboard has become. GPT-5.5 leads at score 60, but five models achieve score 57: Claude Opus 4.7, Gemini 3.1 Pro, and Qwen3.7 Max. A year ago, the gap between #1 and #5 was 20+ points. Today it's just 3 points. This convergence has massive implications for buyers. If GPT-5.5 at $4.35/M scores 60, and Qwen3.7 Max at $1.43/M scores 57, you're paying 3x more for a 5% intelligence improvement. For most production applications, that's not worth it. The practical threshold appears to be around score 50. Models above 50 handle complex multi-step reasoning, nuanced instruction following, and difficult coding tasks reliably. Below 50, quality degrades noticeably on hard tasks but remains excellent for simpler applications like chat, summarization, and basic Q&A. GPT-5.5's lead is most evident at the 'xhigh' effort level, which takes 57 seconds of latency — effectively a batch processing mode. At 'medium' effort (6.8s latency), its score drops to 57, matching its competitors. The intelligence premium is real but comes at a severe latency cost.
OpenAI — GPT-5.5 leads with the highest intelligence score of 60
Cost Efficiency: The 72x Price Spread
The price spread between the most and least expensive models that deliver usable quality is staggering. GPT-5.5 at $4.35/M tokens vs MiMo-V2.5 at $0.06/M tokens — a 72x difference. To put this in perspective: a company processing 1 billion tokens per month would pay $4,350,000/month with GPT-5.5 vs $60,000/month with MiMo-V2.5. The intelligence difference? Score 60 vs 49 — an 18% gap. Our 'Intelligence Per Dollar' metric reveals the clear winners: 1. MiMo-V2.5: Score 49 / $0.06 = 817 IPD 2. DeepSeek V4 Flash: Score 47 / $0.06 = 783 IPD 3. DeepSeek V4 Pro: Score 52 / $0.18 = 289 IPD 4. MiMo-V2.5-Pro: Score 54 / $0.18 = 300 IPD 5. Qwen3.7 Max: Score 57 / $1.43 = 40 IPD Xiaomi's MiMo and DeepSeek models dominate cost efficiency. For the majority of production workloads, these models deliver more than enough intelligence at prices that make AI essentially free. The enterprise premium — paying $4+ per million tokens for GPT-5.5 or Claude Opus 4.7 — is only justified when the marginal intelligence improvement directly impacts revenue or risk. Legal analysis, medical reasoning, and safety-critical applications may warrant it. Customer support, content generation, and data extraction almost certainly do not.
Artificial Analysis leaderboard — the source for our intelligence and pricing data
Speed & Latency: The Forgotten Dimensions
Intelligence scores dominate headlines, but for real-time applications, output speed and latency matter more. The spread here is enormous. Fastest output: Mercury 2 from Inception at 903 tokens/second — 16x faster than Claude Opus 4.7 at 55 t/s. For streaming responses in chat applications, this difference is immediately visible to users. Among top-tier models (score 50+), Qwen3.7 Max stands out at 211 t/s with just 2.5s latency — faster than Gemini 3.5 Flash (212 t/s but 15.4s latency) on first-token delivery. This makes Qwen3.7 the best choice for real-time applications that also need high intelligence. Claude Opus 4.7 in 'max' mode takes 25.6 seconds to first token — acceptable for batch processing but painful for interactive use. Its non-reasoning mode drops to 1.9s latency but also drops the score from 57 to 52. GPT-5.5 at 'xhigh' effort takes a staggering 56.9 seconds to first token. At 'medium' effort, this drops to 6.8s but the score also drops from 60 to 57. The intelligence-latency tradeoff is the defining design decision for any production system. For chat and real-time applications, we recommend targeting models with sub-3s latency and 100+ t/s output: Qwen3.7 Max, Grok 4.3, DeepSeek V4 Pro, or GPT-5.4 mini.
Speed and latency vary dramatically across effort levels and model families
The Rise of Chinese Models
The most significant market shift in 2026 is the emergence of Chinese models as serious contenders across all tiers. Qwen3.7 Max (Alibaba) matches Claude Opus 4.7 and Gemini 3.1 Pro at score 57 — but at $1.43/M tokens, it's 65% cheaper than Claude and 18% cheaper than Gemini. It's also the fastest model at this intelligence level at 211 t/s. MiMo-V2.5-Pro (Xiaomi) achieves score 54 at just $0.18/M tokens. A year ago, score 54 would have placed it in the top 3 globally. Today it's the best open-weights model available. DeepSeek V4 Pro delivers score 52 at $0.18/M tokens — matching Claude Sonnet 4.6's intelligence at 1/14th the price. Kimi K2.6 (Moonshot AI) achieves score 54 at $0.70/M with strong reasoning capabilities. For Western enterprises, the question is no longer 'Are Chinese models good enough?' — they clearly are. The question is 'Can we use them?' Data sovereignty, geopolitical risk, and compliance requirements may prevent some organizations from adopting these models, but the capability gap has effectively closed. For startups, individual developers, and organizations without strict compliance requirements, Chinese models offer the best value in the market today.
Chinese models (Qwen, DeepSeek, MiMo, Kimi) dominate the price-performance frontier
Market Tiers: Four Levels Emerge
The market has consolidated into four distinct tiers: **Frontier Tier (Score 55-60, $1.30-4.35/M):** GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, Qwen3.7 Max, Gemini 3.5 Flash. For the hardest reasoning tasks where every point of accuracy matters. Qwen3.7 Max is the value leader in this tier. **Premium Tier (Score 50-54, $0.18-2.46/M):** Claude Sonnet 4.6, DeepSeek V4 Pro, MiMo-V2.5-Pro, Kimi K2.6, Grok 4.3. Excellent quality for 90%+ of production use cases. DeepSeek V4 Pro and MiMo-V2.5-Pro are standout values at $0.18/M. **Efficient Tier (Score 44-49, $0.06-0.65/M):** MiMo-V2.5, GPT-5.4 mini, Grok 4.3 (medium), DeepSeek V4 Flash. Good enough for most consumer applications, chatbots, and high-volume processing. MiMo-V2.5 at $0.06/M is essentially free. **Budget Tier (Score 36-43, $0.03-0.52/M):** Claude 4.5 Haiku, Gemini 3.5 Flash (minimal), various small models. For simple tasks, embedding, classification, and routing. Useful as the 'cheap' model in multi-model architectures. The optimal strategy for most teams: use a Premium tier model as your default, route the hardest 10% of queries to a Frontier model, and handle high-volume simple tasks with an Efficient tier model. This can reduce costs 60-80% compared to running everything through GPT-5.5.
Open-Weights Models: Closing the Gap
Open-weights models have made enormous progress. Kimi K2.6 and MiMo-V2.5-Pro both achieve score 54 — a level that would have been frontier-class just 12 months ago. For organizations that need self-hosted deployment (healthcare, finance, government, defense), the options have never been better: - MiMo-V2.5-Pro (score 54): Best overall open-weights model - Kimi K2.6 (score 54): Strong reasoning variant available - Qwen3.6 Plus (score 50): Alibaba's open model, competitive with proprietary offerings - Gemma 4 31B (score 39): Google's open model, good for on-device use - Llama 4 Maverick (score 18): Meta's latest, but significantly behind the Chinese alternatives A notable development: Meta's Llama, once the undisputed leader in open models, has fallen significantly behind. Llama 4 Maverick scores just 18, while Chinese open models achieve 49-54. This reflects both the rapid pace of Chinese AI development and the challenges Meta faces in keeping pace. For fine-tuning use cases, open-weights models remain essential. You can't fine-tune GPT-5.5 or Claude Opus 4.7. But you can fine-tune MiMo-V2.5-Pro or Qwen3.6 on your domain data to potentially exceed proprietary model performance for your specific use case.
Open-weights models have closed the gap with proprietary alternatives
Reasoning Modes: A New Paradigm
A major architectural trend in 2026 is the separation of 'reasoning' and 'non-reasoning' modes within the same model family. Claude Opus 4.7 scores 57 in reasoning mode but 52 in non-reasoning mode. DeepSeek V4 Pro scores 52 in reasoning mode but drops to 39 without it. Grok 4.3 goes from 53 to 31. This has profound implications for production architectures. Reasoning mode delivers higher intelligence but at significantly higher latency and cost (more compute per query). Non-reasoning mode is faster and cheaper but less capable on hard tasks. The smart architecture: route each query to the appropriate mode. Simple queries (greeting, FAQ, summarization) → non-reasoning mode. Complex queries (analysis, multi-step reasoning, coding) → reasoning mode. This can cut costs 40-60% while maintaining quality on hard tasks. Some platforms (GPT-5.5, Grok 4.3) offer multiple effort levels within reasoning mode — from 'low' (fast, cheaper) to 'xhigh' (slow, expensive, most intelligent). GPT-5.5 scores range from 51 (low effort) to 60 (xhigh effort), with latency ranging from 2s to 57s. This granularity enables very precise cost-quality-speed optimization.
Conclusion & Recommendations
The LLM market in Q2 2026 is defined by convergence at the top and commoditization at the bottom. The intelligence gap between the best and tenth-best model is just 10 points. The price gap is 72x. Choosing the right model is primarily a cost and latency optimization problem, not an intelligence problem.
GPT-5.5 (high effort) or Claude Opus 4.7 (max)
When errors are extremely costly, the extra 3-5 intelligence points justify the premium. Use xhigh effort only for the hardest problems.
Qwen3.7 Max
Matches Claude Opus 4.7 intelligence (score 57) at $1.43/M — 65% cheaper. Fastest model at this tier (211 t/s). Best choice if geopolitical concerns aren't a blocker.
DeepSeek V4 Pro or MiMo-V2.5-Pro
Score 52-54 at $0.18/M tokens. 90% of premium quality at 4% of the cost. The sweet spot for most production workloads.
Grok 4.3 (high) or Qwen3.7 Max
Both combine high intelligence (53-57) with fast output speed (190-211 t/s) and reasonable latency. Best for user-facing interactive applications.
MiMo-V2.5 or DeepSeek V4 Flash
Score 47-49 at $0.06/M tokens. For applications processing millions of requests daily where good-enough quality is sufficient.
MiMo-V2.5-Pro or Kimi K2.6
Best open-weights models at score 54. Full control over infrastructure and data. Essential for regulated industries.
Methodology
Benchmark data aggregated from LMSYS Chatbot Arena (ELO ratings as of May 2026), MMLU, GPQA Diamond, HumanEval+, MATH-500, and custom BestAI evaluation tasks. We verified published benchmark claims by running a subset of tests independently. Cost analysis based on published API pricing as of May 2026. For open-source models, costs are estimated based on Replicate/Modal/Together AI hosting. Community sentiment aggregated from 3,800+ discussions across Reddit, HN, and Twitter from Q1-Q2 2026.
Learn more about our evaluation methodology →Our Verdict
The era of 'just use GPT-4' is definitively over. GPT-5.5 leads on raw intelligence but at a price premium that's hard to justify for most applications. Qwen3.7 Max is the revelation — matching Claude Opus 4.7 at 65% lower cost with 4x the output speed. For cost-sensitive production use, DeepSeek V4 Pro and MiMo-V2.5-Pro at $0.18/M tokens make premium AI essentially a rounding error. The right strategy is multi-model: route hard queries to the Frontier tier, everything else to the Premium or Efficient tier.
Disclosure: This report was produced by BestAI LLC using a combination of automated agent-based testing and data analysis. Benchmark results reflect testing conducted as of May 10, 2026 and may change as tools release updates. BestAI has no financial relationship with any of the tools evaluated in this report. For questions about our methodology, see our evaluation methodology page.
Tools Evaluated
Report Details
More Reports
The AI discovery platform. Deep analysis, honest comparisons, and real metrics to help you find the best AI for any task.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









