EchoMimic
by Alibaba's Ant GroupWhat is EchoMimic?
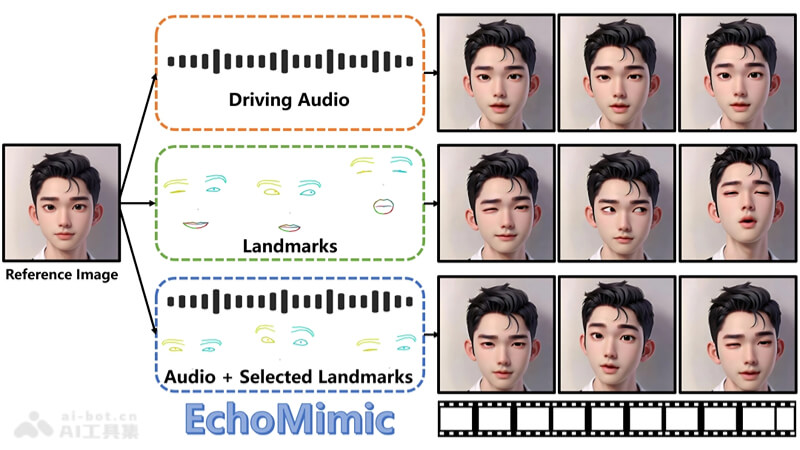
EchoMimic is an open-source AI digital human project launched by Alibaba's Ant Group, designed to bring static images to life with voice and expressions. By combining deep learning models with audio and facial landmarks, it creates highly realistic dynamic portrait videos. It supports generating videos using either audio or facial features alone, or combining both for more natural and smooth lip-syncing effects. EchoMimic is multilingual, supporting both Chinese and English, and is suitable for various scenarios such as singing, bringing revolutionary advancements to digital human technology, widely used in entertainment, education, and virtual reality fields.
Features of EchoMimic
- Audio-synchronized Animation: By analyzing audio waveforms, EchoMimic can precisely generate lip-syncing and facial expressions synchronized with speech, bringing static images to life.
- Facial Feature Fusion: The project uses facial landmark technology to capture and simulate the movements of key areas such as eyes, nose, and mouth, enhancing the realism of the animation.
- Multimodal Learning: By combining audio and visual data, EchoMimic improves the naturalness and expressiveness of animations through multimodal learning methods.
- Cross-language Capability: Supports multiple languages including Chinese Mandarin and English, allowing users from different language regions to create animations.
- Style Diversity: EchoMimic can adapt to different performance styles, including daily conversations and singing, providing users with a wide range of application scenarios.

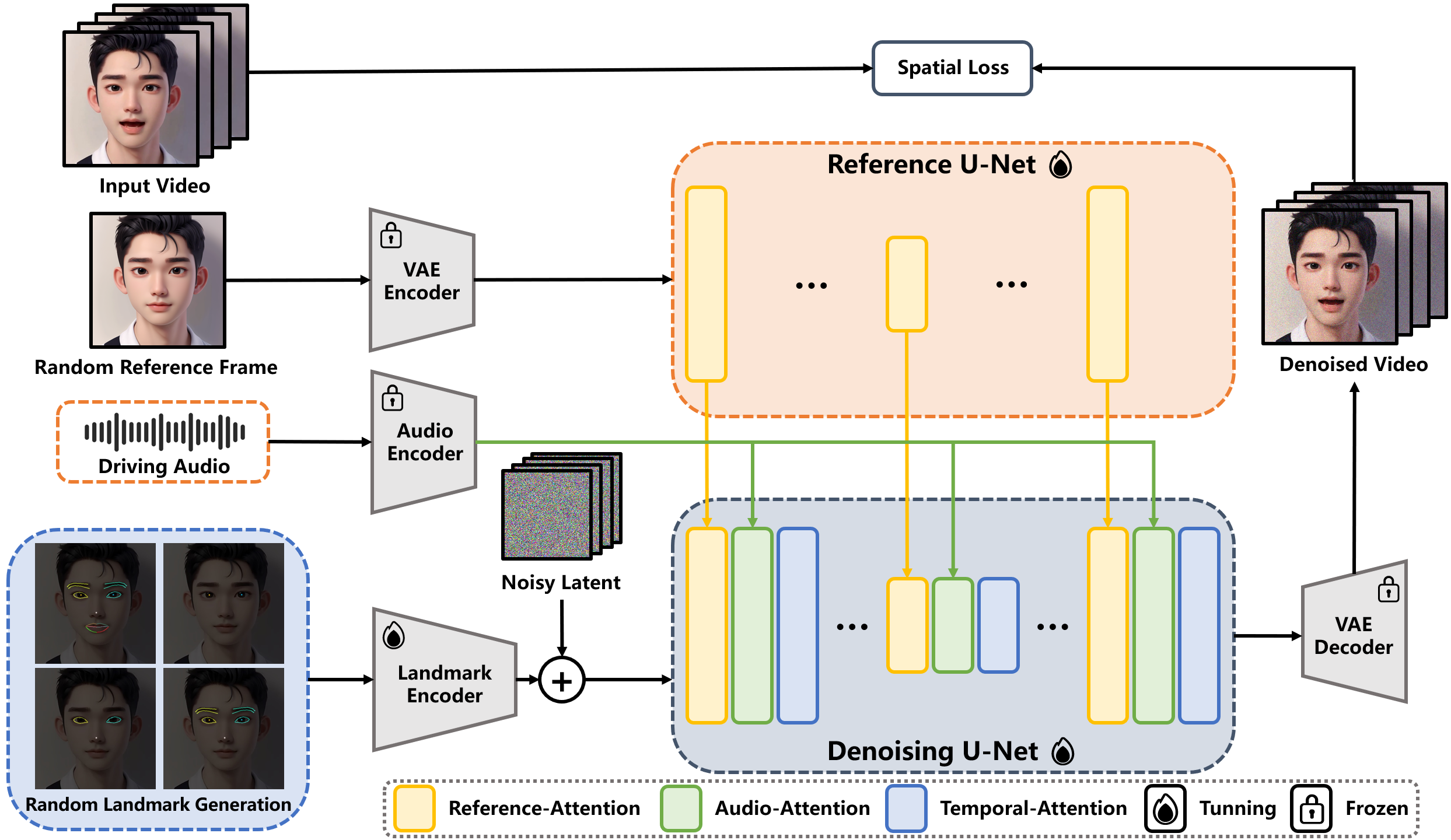
Technical Principles of EchoMimic
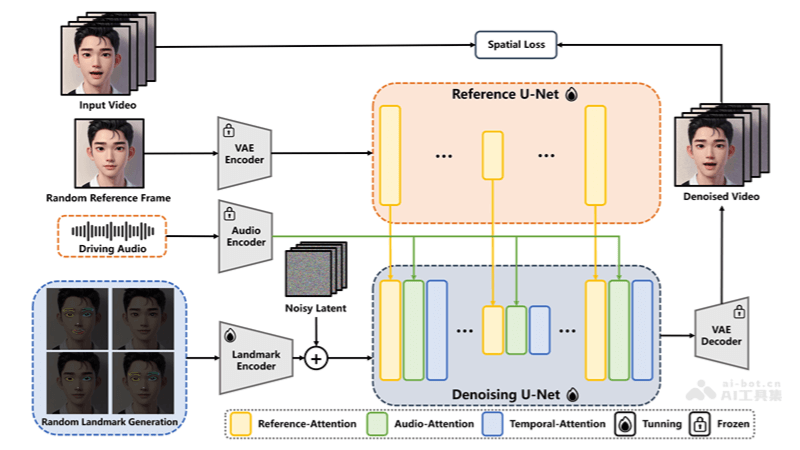
- Audio Feature Extraction: EchoMimic first deeply analyzes the input audio, using advanced audio processing techniques to extract key features such as rhythm, pitch, and intensity.
- Facial Landmark Localization: Through high-precision facial recognition algorithms, EchoMimic can accurately locate key facial areas, including lips, eyes, and eyebrows, providing a foundation for subsequent animation generation.
- Facial Animation Generation: Combining audio features and facial landmark positions, EchoMimic uses complex deep learning models to predict and generate facial expressions and lip-syncing synchronized with speech.
- Multimodal Learning: The project adopts a multimodal learning strategy, deeply integrating audio and visual information, ensuring that the generated animations are not only visually realistic but also semantically consistent with the audio content.
- Deep Learning Model Applications:
- Convolutional Neural Network (CNN): Used to extract features from facial images.
- Recurrent Neural Network (RNN): Processes the temporal dynamics of audio signals.
- Generative Adversarial Network (GAN): Generates high-quality facial animations, ensuring the realism of visual effects.
- Innovative Training Methods: EchoMimic employs innovative training strategies, allowing the model to use audio and facial landmark data independently or in combination to improve the naturalness and expressiveness of animations.
- Pre-training and Real-time Processing: The project uses models pre-trained on large datasets, enabling EchoMimic to quickly adapt to new audio inputs and generate facial animations in real-time.
Getting Started with EchoMimic
To get started with EchoMimic, visit the GitHub repository for detailed installation instructions and usage examples. The project is open-source and free to use, making it accessible for developers and researchers interested in digital human technology.
Features & Capabilities
- Entertainment
- Education
- Virtual Reality
- Singing
- Conversational Agents
Getting Started
Screenshots & Images