EchoMimicV2
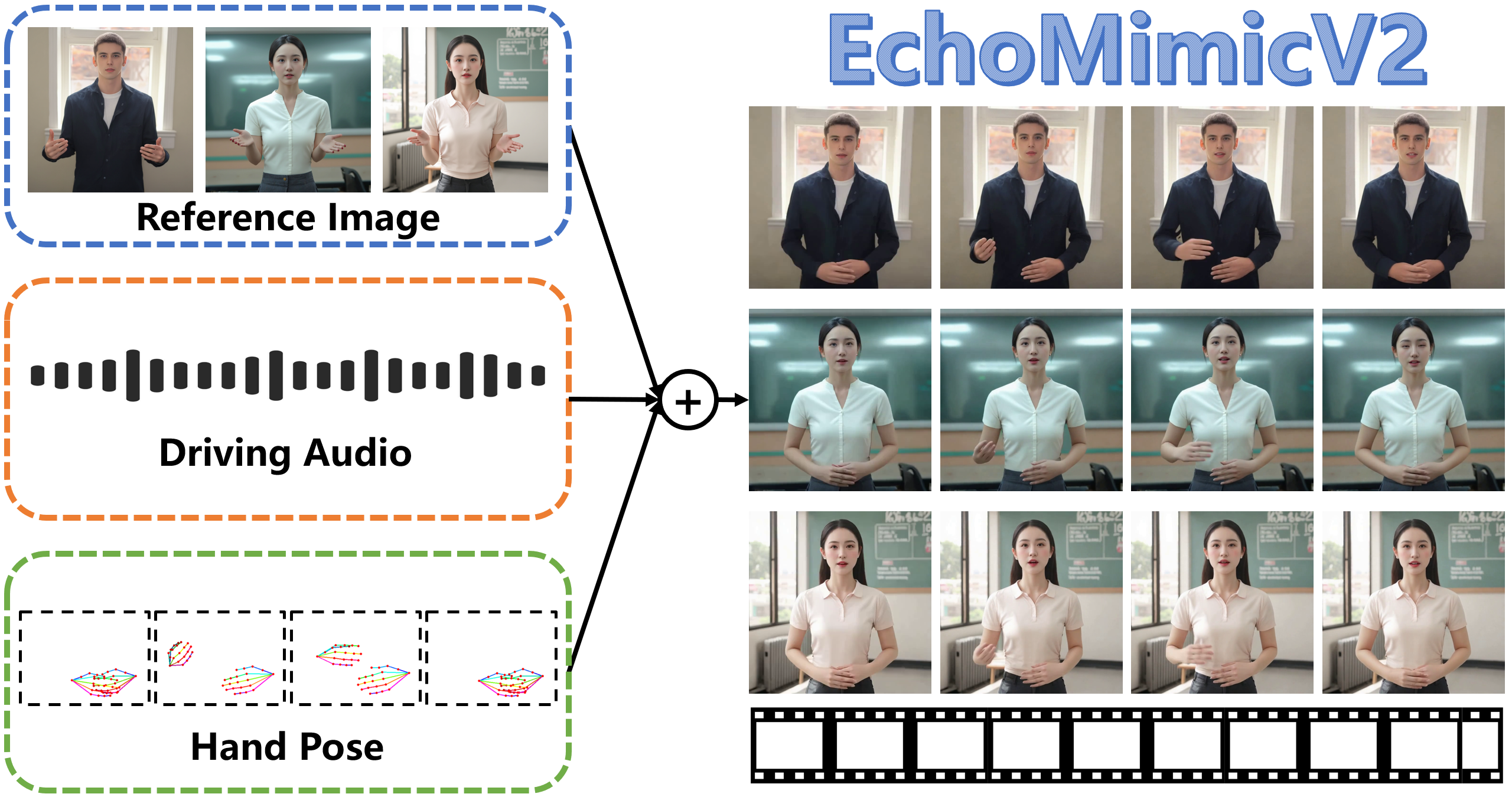
by Alibaba's Ant GroupEchoMimicV2 is a digital human project by Alibaba's Ant Group that generates high-quality animation videos from reference images, audio clips, and hand pose sequences, ensuring audio and upper body motion synchronization.
What is EchoMimicV2?
EchoMimicV2 is a digital human project developed by Alibaba's Ant Group, designed to generate high-quality animation videos based on reference images, audio clips, and hand pose sequences. It ensures synchronization between audio content and upper body movements. Building on the previous EchoMimicV1, which focused on realistic head animations, EchoMimicV2 now generates full upper body animations, seamlessly converting Chinese and English speech into corresponding movements.
Main Features of EchoMimicV2
- Audio-Driven Animation Generation: Uses audio clips to drive facial expressions and body movements, ensuring synchronization between audio and animation.
- Upper Body Animation Production: Extends from generating only head animations to producing animations that include the upper body.
- Simplified Control Conditions: Reduces the complexity of conditions required during animation generation, making the process more straightforward.
- Gesture and Expression Synchronization: Combines hand pose sequences with audio to generate natural and synchronized gestures and facial expressions.
- Multilingual Support: Supports both Chinese and English, generating animations based on the language content.
Technical Principles of EchoMimicV2
- Audio-Pose Dynamic Coordination (APDH):
- Pose Sampling: Gradually reduces dependency on pose conditions, allowing audio conditions to play a more significant role in the animation.
- Audio Diffusion: Expands the influence of audio conditions from the lips to the entire face and then to the body, enhancing synchronization between audio and animation.
- Head Partial Attention (HPA): Integrates head data during training, enhancing facial expression details without requiring additional plugins or modules.
- Phase-Specific Denoising Loss (PhD Loss): Divides the denoising process into three phases: pose-dominant, detail-dominant, and quality-dominant, each with specific optimization goals.
- Latent Diffusion Model (LDM): Uses a Variational Autoencoder (VAE) to map images to a latent space, gradually adding noise during training and estimating and removing noise at each timestep.
- ReferenceNet-based Backbone: Uses ReferenceNet to extract features from reference images, injecting them into the denoising U-Net to maintain consistency between generated and reference images.
Application Scenarios of EchoMimicV2
- Virtual Anchors: Create virtual news anchors or live streamers for broadcasting in Chinese or English, improving content production efficiency and diversity.
- Online Education: Produce virtual teachers or instructors for online courses and training, making educational resources more abundant and accessible.
- Entertainment and Gaming: Create realistic non-player characters (NPCs) in games, providing more natural and smooth interaction experiences.
- Film and Video Production: Use in motion capture and post-production, reducing the cost and complexity of actual shooting and improving production efficiency.
- Customer Service: Serve as virtual customer service representatives, offering multilingual customer support to enhance service quality and response speed.
Features & Capabilities
What You Can Do
Animation Generation
Audio Synchronization
Gesture Recognition
Multilingual Support
Categories
Digital Human
Animation
AI
Audio-Driven
Upper Body Animation
Multilingual Support
Virtual Anchors
Online Education
Entertainment
Film Production
Example Uses
- Virtual Anchors
- Online Education
- Entertainment and Gaming
- Film and Video Production
- Customer Service
Getting Started
Pricing
free
Free to use
Screenshots & Images
Primary Screenshot

Additional Images




Stats
84
Views
0
Favorites









