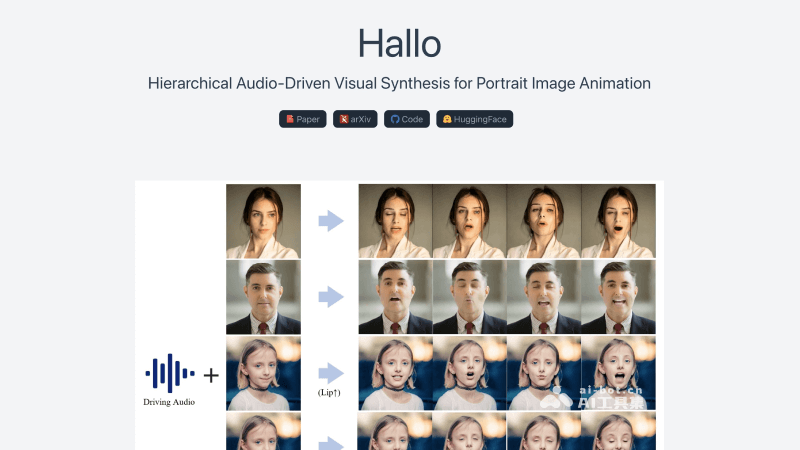
Hallo
Hallo is an AI-driven lip-syncing portrait animation technology that generates realistic and dynamic portrait videos based on voice audio input.
What is Hallo?
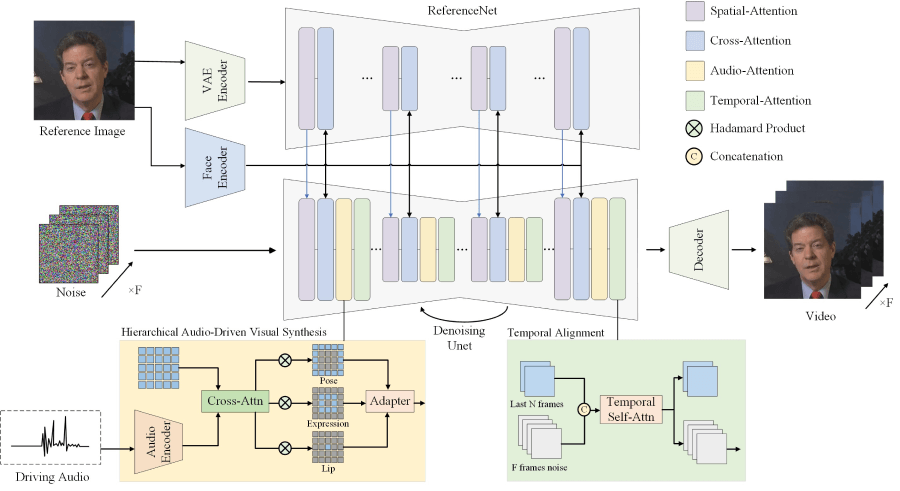
Hallo is an AI-driven lip-syncing portrait animation technology proposed by researchers from Fudan University, Baidu, ETH Zurich, and Nanjing University. It can generate realistic and dynamic portrait image videos based on voice audio input. The framework uses a diffusion-based generative model and a hierarchical audio-driven visual synthesis module to improve the synchronization accuracy between audio and visual output. Hallo's network architecture integrates a UNet denoiser, time alignment technology, and a reference network to enhance the quality and realism of the animation, significantly improving image and video quality, lip-sync accuracy, and motion diversity.
Features of Hallo
- Audio-Synchronized Animation: Hallo uses advanced audio analysis technology to combine input voice audio with portrait images, generating dynamic facial animations. The precise lip-sync algorithm ensures that the lip movements in the video animation are synchronized with the audio, creating a realistic speaking effect.
- Facial Expression Generation: Based on the emotional and tonal changes in the audio signal, Hallo can automatically recognize and generate corresponding facial expressions, including smiles, frowns, and surprise, making the video animation character's "performance" more natural and emotional.
- Head Pose Control: Hallo allows for detailed adjustments to the head pose in the video animation, such as tilting and turning, enabling the video animation to better reflect the intent and emotion of the audio content, enhancing the coordination between visual and auditory elements.
- Personalized Animation Customization: Users can customize the animation's style, expressions, and actions based on different application scenarios and personal characteristics. Hallo's personalized customization feature allows users to create unique characters that meet specific visual and emotional expression needs.
- Temporal Consistency Maintenance: Hallo ensures smooth transitions of actions and expressions over time through time alignment technology, avoiding abrupt and unnatural changes.
- Motion Diversity: In addition to basic audio-synchronized actions, Hallo supports the generation of diverse actions and styles. Users can select different motion libraries as needed to add more dynamic elements to the animation character, such as gestures and blinks, enriching the video's expressiveness.
Official Links for Hallo
- Official Project Homepage: https://fudan-generative-vision.github.io/hallo/#/
- GitHub Repository: https://github.com/fudan-generative-vision/hallo
- Hugging Face Model Library: https://huggingface.co/fudan-generative-ai/hallo
- arXiv Technical Paper: https://arxiv.org/abs/2406.08801
Technical Principles of Hallo
- Hierarchical Audio-Driven Visual Synthesis: Hallo uses a hierarchical approach to process audio and visual information. This hierarchical structure allows the model to separately handle lip movements, facial expressions, and head poses, then fuse these elements together through adaptive weights.
- End-to-End Diffusion Model: Hallo uses a diffusion-based generative model, a method that generates data from a latent space. During the training phase, noise is gradually added to the data, and then the noise is removed in the reverse process to reconstruct clear images.
- Cross-Attention Mechanism: Through the cross-attention mechanism, Hallo can establish connections between audio features and visual features. This mechanism allows the model to focus on the facial regions most relevant to the current audio input.
- UNet Denoiser: Hallo uses a UNet-based denoiser to gradually remove noise from images, generating clear animation frames. The UNet structure is known for its effectiveness in image segmentation tasks, using low-level feature maps through skip connections to improve generation quality.
- Time Alignment Technology: To maintain temporal coherence in animations, Hallo employs time alignment technology, which helps ensure smooth transitions and consistency between consecutive frames.
- Reference Network (ReferenceNet): ReferenceNet is used to encode global visual texture information to achieve consistent and controllable character animation. It helps the model reference existing images during the generation process to enhance the visual quality of the output.
- Facial and Audio Encoders: Hallo uses a pre-trained facial encoder to extract identity features from portraits and an audio feature encoder (e.g., wav2vec) to convert audio signals into information that can drive animation movements.
- Adaptive Weight Adjustment: Hallo allows for the adjustment of weights for different visual components (e.g., lips, expressions, poses) to control the diversity and detail of the animation.
- Training and Inference: During the training phase, Hallo optimizes the parameters of the facial image encoder and spatial cross-attention modules to improve single-frame generation capabilities. During the inference phase, the model combines reference images and driving audio to generate animation video sequences.
Features & Capabilities
Categories
AI Lip-Syncing
Portrait Animation
Voice-Driven Video
Getting Started
Screenshots & Images
Additional Images