MinerU
by OpenDataLabMinerU is an open-source intelligent data extraction tool by OpenDataLab, focusing on efficient parsing and extraction of complex PDF documents.
What is MinerU?
MinerU is an open-source intelligent data extraction tool developed by OpenDataLab. It specializes in parsing and extracting content from complex PDF documents that include images, formulas, tables, and other elements. MinerU converts these multi-modal PDFs into Markdown format, making them easier to analyze. It also supports content extraction from web pages and e-books, enhancing AI corpus preparation.
Key Features of MinerU
- PDF to Markdown Conversion: Converts PDF documents with various content types into structured Markdown format.
- Multi-modal Content Processing: Identifies and processes images, formulas, tables, and text within PDFs.
- Structure and Format Preservation: Maintains the original document's structure and format.
- Formula Recognition and Conversion: Specifically identifies mathematical formulas and converts them to LaTeX format.
- Interference Element Removal: Automatically removes non-content elements such as headers, footers, and page numbers.
- Garbled Text Recognition and Handling: Automatically identifies and corrects garbled text in PDF documents.
- High-Quality Parsing Toolchain: Integrates advanced PDF parsing tools, including layout detection, formula detection, and OCR.
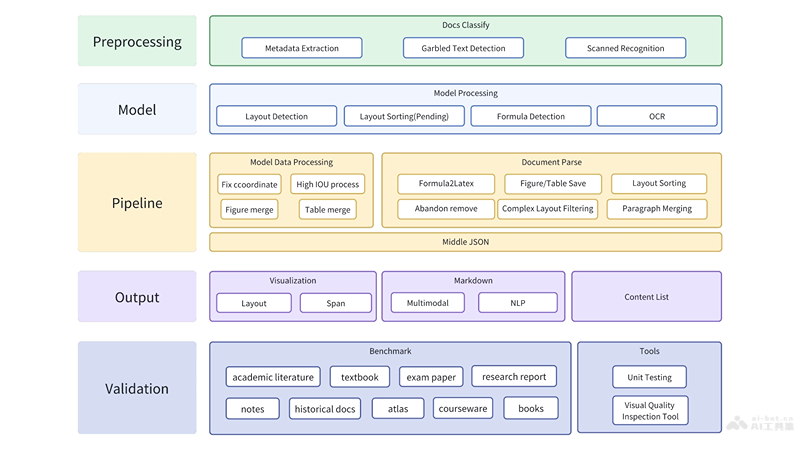
Technical Principles of MinerU
- PDF Document Classification and Preprocessing: Classifies PDFs and performs preprocessing.
- Model Parsing and Content Extraction: Uses deep learning models for layout detection, formula detection, and OCR.
- Pipeline Processing: Processes data from model parsing, including block-level order determination and content sorting.
- Multiple Format Outputs: Outputs processed document information in various formats.
- PDF Extraction Quality Check: Uses a manually annotated PDF self-evaluation dataset to test the entire process.
MinerU Project Addresses
- Project Website: https://opendatalab.com/OpenSourceTools/Extractor/PDF
- GitHub Repository: https://github.com/opendatalab/PDF-Extract-Kit
- HuggingFace Model Library: https://huggingface.co/wanderkid/PDF-Extract-Kit
- ModelScope Community Model Library: https://www.modelscope.cn/models/wanderkid/PDF-Extract-Kit
Application Scenarios of MinerU
- Academic Research: Extract key information from academic papers and journals.
- Legal Document Processing: Extract clauses and evidence from contracts and legal opinions.
- Technical Document Management: Extract technical specifications and operational steps from manuals.
- Knowledge Management and Information Retrieval: Build knowledge bases from internal document libraries.
- Data Mining and NLP: Use extracted data to train and optimize machine learning models.
Features & Capabilities
What You Can Do
Pdf To Markdown Conversion
Formula Recognition
Text Extraction
Document Parsing
Content Structure Preservation
Categories
PDF Extraction
Data Parsing
Markdown Conversion
AI Tools
Open Source
Text Recognition
Formulas
Tables
Web Scraping
Document Processing
Example Uses
- Academic Research
- Legal Document Processing
- Technical Document Management
- Knowledge Management
- Data Mining
Getting Started
Pricing
free
Screenshots & Images
Primary Screenshot
Additional Images