PersonaTalk
PersonaTalk is a two-stage framework by ByteDance that achieves high-fidelity and personalized visual dubbing, ensuring precise lip-sync and retaining the speaker's unique style and facial details.
What is PersonaTalk?
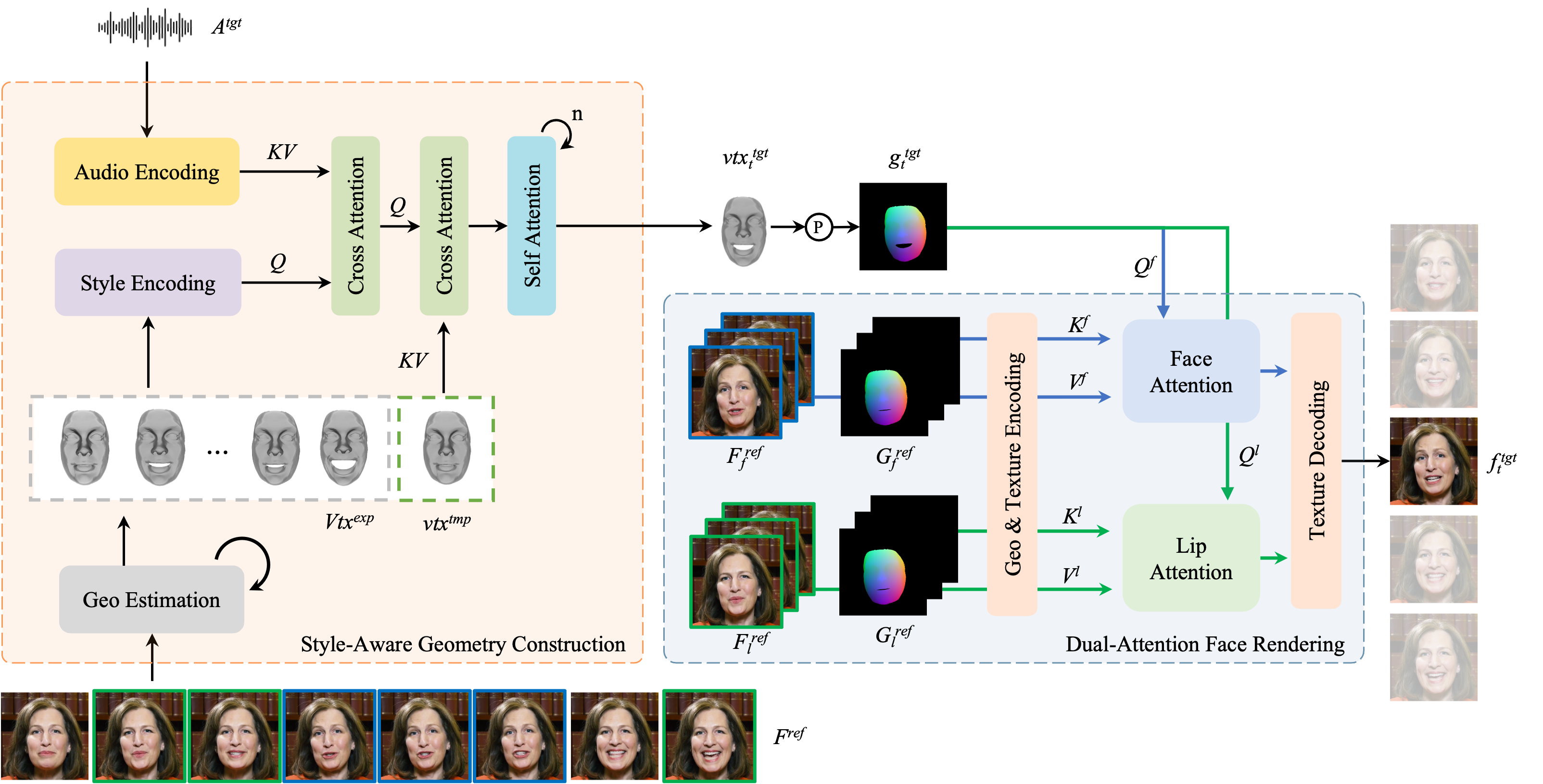
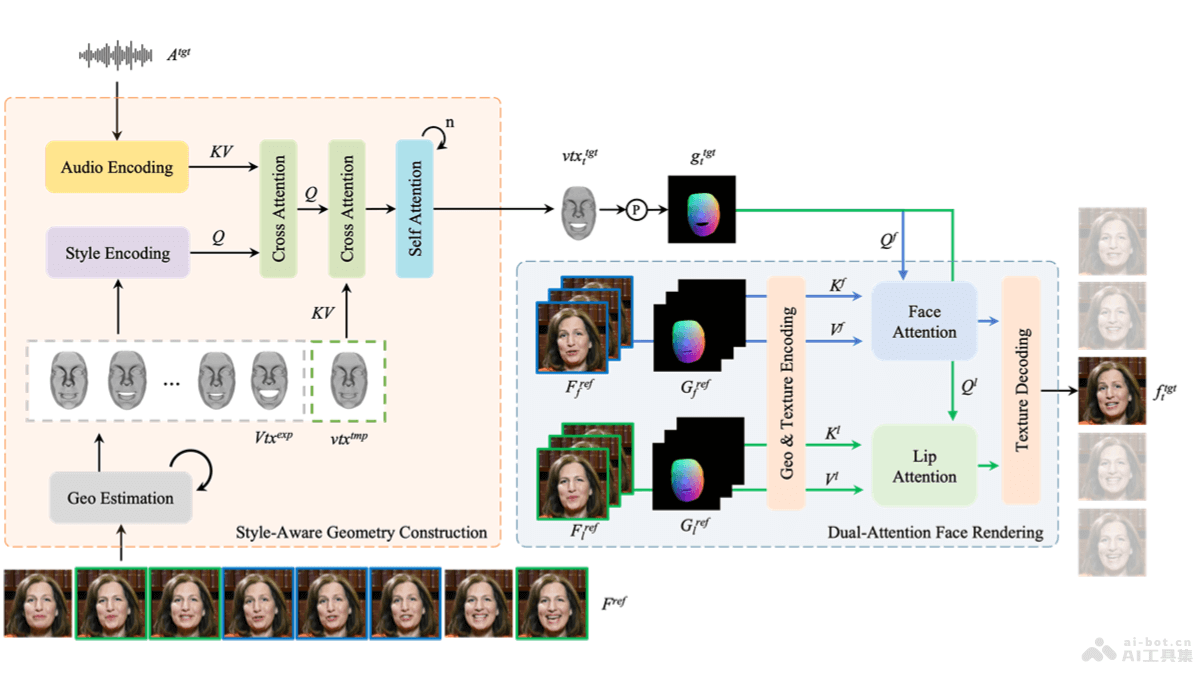
PersonaTalk is a two-stage framework developed by ByteDance, based on an attention mechanism, designed to achieve high-fidelity and personalized visual dubbing. It synthesizes videos with precise lip-sync to the target audio while preserving the speaker's unique speaking style and facial details. The first stage involves style-aware audio encoding and lip-sync geometry generation, and the second stage uses a dual-attention facial renderer to texture the target geometry. PersonaTalk outperforms existing technologies (including Wav2Lip, VideoReTalking, DINet, and IP_LAP) in visual quality, lip-sync accuracy, and personality retention, achieving results comparable to person-specific methods as a general framework.
Key Features of PersonaTalk
- Lip-Sync: Ensures that the character's mouth movements in the video precisely match the input audio.
- Personality Retention: Preserves the speaker's unique style and facial features during video synthesis.
- Style Awareness: Analyzes the speaker's 3D facial geometry to learn their speaking style and integrates it into the audio features.
- Dual-Attention Facial Rendering: Uses two parallel attention mechanisms, Lip-Attention and Face-Attention, to handle the texture rendering of the lips and other facial areas, generating detailed facial images.
Technical Principles of PersonaTalk
- Geometry Construction:
- Style-Aware Audio Encoding: Uses pre-trained models like HuBERT to convert audio signals into rich contextual speech representations, injecting speaking style into audio features via cross-attention layers.
- Lip-Sync Geometry Generation: Drives the speaker's template geometry with stylized audio features, generating lip-sync geometry synchronized with the audio through multiple cross-attention and self-attention layers.
- Facial Rendering:
- Geometry and Texture Encoding: Encodes the geometry and texture of the reference video into a latent space for subsequent processing.
- Dual-Attention Texture Sampling: Samples lip and facial textures from different reference frames using two parallel cross-attention layers (Lip-Attention and Face-Attention).
- Reference Frame Selection Strategy: Selects different reference frames for lip and facial textures to enhance the diversity and global consistency of texture sampling.
- Texture Decoding: Decodes the sampled textures from the latent space back to the pixel space, preserving facial geometry and generating the final facial image.
PersonaTalk Project Links
- Project Website: grisoon.github.io/PersonaTalk
- arXiv Technical Paper: https://arxiv.org/pdf/2409.05379
Application Scenarios of PersonaTalk
- Film and Video Production: In post-production, PersonaTalk can dub characters, especially when the original recording is unsatisfactory or needs language changes, generating lip-sync dubbing videos.
- Video Games: In game development, it can generate realistic dialogues for non-player characters (NPCs), providing a more immersive gaming experience.
- Virtual Assistants and Digital Humans: Offers more natural and realistic speech and facial expression synchronization for virtual assistants or digital humans, enhancing user interaction.
- Language Learning Applications: In language learning software, it can generate lip-sync videos of teachers or virtual characters, helping learners better learn and imitate pronunciation.
- News and Media Broadcasting: Can translate news anchors' speeches into different languages while maintaining original facial expressions and lip movements, improving the naturalness and accuracy of multilingual broadcasts.
Features & Capabilities
Categories
Visual Dubbing
Lip-Sync
Facial Rendering
Getting Started
Screenshots & Images
Additional Images
Stats
86
Views
0
Favorites









