SadTalker
by Xi'an Jiaotong University, Tencent AI Lab, Ant GroupSadTalker is an open-source AI digital human project that generates realistic talking face animations from a single face image and audio using 3D motion coefficients.
What is SadTalker?
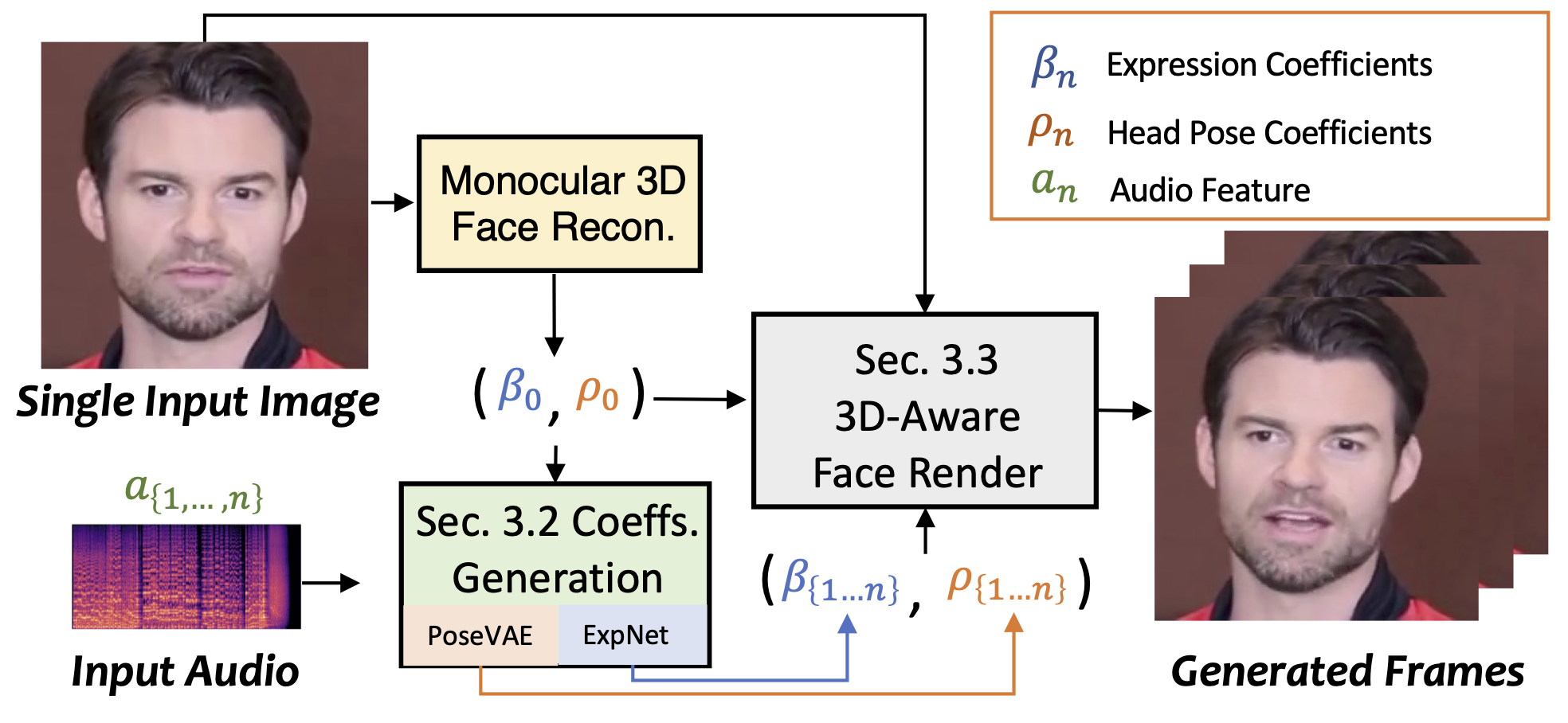
SadTalker is an open-source AI digital human project developed by Xi'an Jiaotong University, Tencent AI Lab, and Ant Group. It generates realistic talking face animations from a single face image and audio using 3D motion coefficients. The tool is designed to create high-quality, stylized video animations that are synchronized with audio inputs.
Main Features of SadTalker
- 3D Motion Coefficient Generation: Extracts 3D motion coefficients for head pose and expressions from audio.
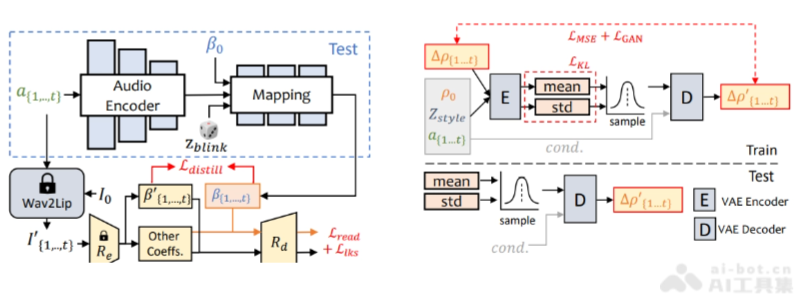
- ExpNet: A specially designed network for learning accurate facial expressions from audio.
- PoseVAE: A conditional variational autoencoder for synthesizing different styles of head movements.
- 3D Facial Rendering: Maps 3D motion coefficients to 3D keypoint space for rendering stylized facial animations.
- Multilingual Support: Capable of processing audio inputs in different languages to generate corresponding talking animations.
Technical Principles of SadTalker
- 3D Motion Coefficient Learning: SadTalker learns 3D motion coefficients, including head pose and facial expressions, by analyzing audio signals.
- ExpNet (Expression Network): Extracts facial expression information from audio, generating accurate facial expression animations.
- PoseVAE (Head Pose Variational Autoencoder): A conditional variational autoencoder that generates different styles of head movements.
- 3D Facial Rendering: Uses a novel 3D facial rendering technique to map learned 3D motion coefficients to 3D keypoint space.
- Multimodal Learning: Considers both audio and visual information during training, improving the naturalness and accuracy of animations.
- Stylized Processing: Generates face animations in different styles, adapting to various visual styles.
- Unsupervised Learning: Employs unsupervised learning methods to generate 3D keypoints without extensive labeled data.
- Data Fusion: Fuses audio and visual data to generate talking face animations that are synchronized with audio and have natural expressions.
Project Addresses of SadTalker
- GitHub Repository: https://sadtalker.github.io/
- Hugging Face Model Library: https://huggingface.co/spaces/vinthony/SadTalker
- arXiv Technical Paper: https://arxiv.org/pdf/2211.12194
Application Scenarios of SadTalker
- Virtual Assistants and Customer Service: Provides realistic facial animations for virtual assistants or online customer service, enhancing user experience.
- Video Production: Used in video production to generate character facial animations, saving the cost and time of traditional motion capture.
- Language Learning Applications: Offers pronunciation and facial expressions in different languages for language learning software, helping learners better understand and imitate.
- Social Media and Entertainment: Users can create personalized virtual avatars for sharing on social media or entertainment content.
- Education and Training: Provides virtual avatars for instructors in remote teaching or online training, enhancing interactivity.
Features & Capabilities
What You Can Do
Facial Animation
Video Production
Language Learning
Virtual Assistants
Categories
AI
Digital Human
Animation
Open Source
3D Motion Coefficients
Facial Animation
Multilingual Support
Video Production
Virtual Assistants
Language Learning
Example Uses
- Virtual Assistants and Customer Service
- Video Production
- Language Learning Applications
- Social Media and Entertainment
- Education and Training
Getting Started
Pricing
free
Screenshots & Images
Primary Screenshot
Additional Images
Stats
337
Views
0
Favorites









