All Models Complete list of AI models and foundation models, sorted by newest first
Light-R1 is an open-source AI model developed by 360 Smart Brain, focusing on long chain reasoning in mathematics. It is based on Qwen2.5-32B-Instruct and trained with 70,000 mathematical data points using a two-stage curriculum learning approach (SFT+DPO). Light-R1 outperforms DeepSeek-R1-Distill-Qwen-32B, scoring 76.6 in the AIME24 test compared to DeepSeek's 72.6. The model is cost-efficient, requiring only 12 H800 machines running for 6 hours, costing approximately $1000. Light-R1 is fully open-source, including the model, dataset, training framework, and evaluation code, making it a valuable resource for the open-source community and a reference for low-cost training of specialized models.

QwQ-32B is Alibaba's open-source reasoning model with 32 billion parameters, trained using large-scale reinforcement learning (RL). It excels in tasks such as mathematical reasoning and programming, matching the performance of larger models like DeepSeek-R1. The model integrates agent capabilities, adjusting its reasoning process based on environmental feedback, demonstrating strong adaptability and reasoning power. Available on Hugging Face under the Apache 2.0 license, QwQ-32B highlights the potential of reinforcement learning in enhancing model performance and provides new directions for the development of Artificial General Intelligence (AGI).

BGE-VL is a multimodal vector model developed by the Beijing Academy of Artificial Intelligence in collaboration with several universities. It is trained on large-scale synthetic data called MegaPairs and specializes in multimodal retrieval tasks such as image-text retrieval and composite image retrieval. The model enhances generalization and retrieval performance through efficient multimodal data synthesis methods. BGE-VL includes variants like BGE-VL-Base and BGE-VL-Large based on the CLIP architecture, and BGE-VL-MLLM based on a multimodal large model architecture. It has demonstrated excellent performance in various benchmarks, particularly in composite image retrieval tasks, significantly improving retrieval accuracy. The core strengths of BGE-VL lie in the scalability and high quality of its data synthesis methods, as well as its exceptional generalization capabilities in multimodal tasks.

SpatialVLA is a spatial-enhanced vision-language-action model developed by Shanghai AI Lab, China Telecom AI Research Institute, and ShanghaiTech. It is pre-trained on 1.1 million real robot episodes and equipped with 3D Egocentric Position Encoding and Adaptive Spatial Grids. The model excels in 3D scene spatial understanding, zero-shot in-distribution generalization, and efficient adaptation to new robot setups. It achieves state-of-the-art performance across diverse evaluations and offers faster inference speed with fewer tokens per action. The open-source code and flexible fine-tuning mechanisms provide new technical pathways for robotics research and applications.

GEN3C is a generative video model developed by NVIDIA, the University of Toronto, and the Vector Institute. It generates high-quality 3D video content by leveraging precise camera control and spatiotemporal consistency. The model constructs a 3D cache based on point clouds, using depth estimation from input images or video frames to back-project and generate 3D scenes. It then renders 2D videos based on user-provided camera trajectories, ensuring precise control over camera motion and avoiding inconsistencies found in traditional methods. GEN3C supports video generation from single to multiple viewpoints, making it suitable for both static and dynamic scenes. It also supports 3D editing and complex camera movements, providing powerful tools for video creation and simulation.
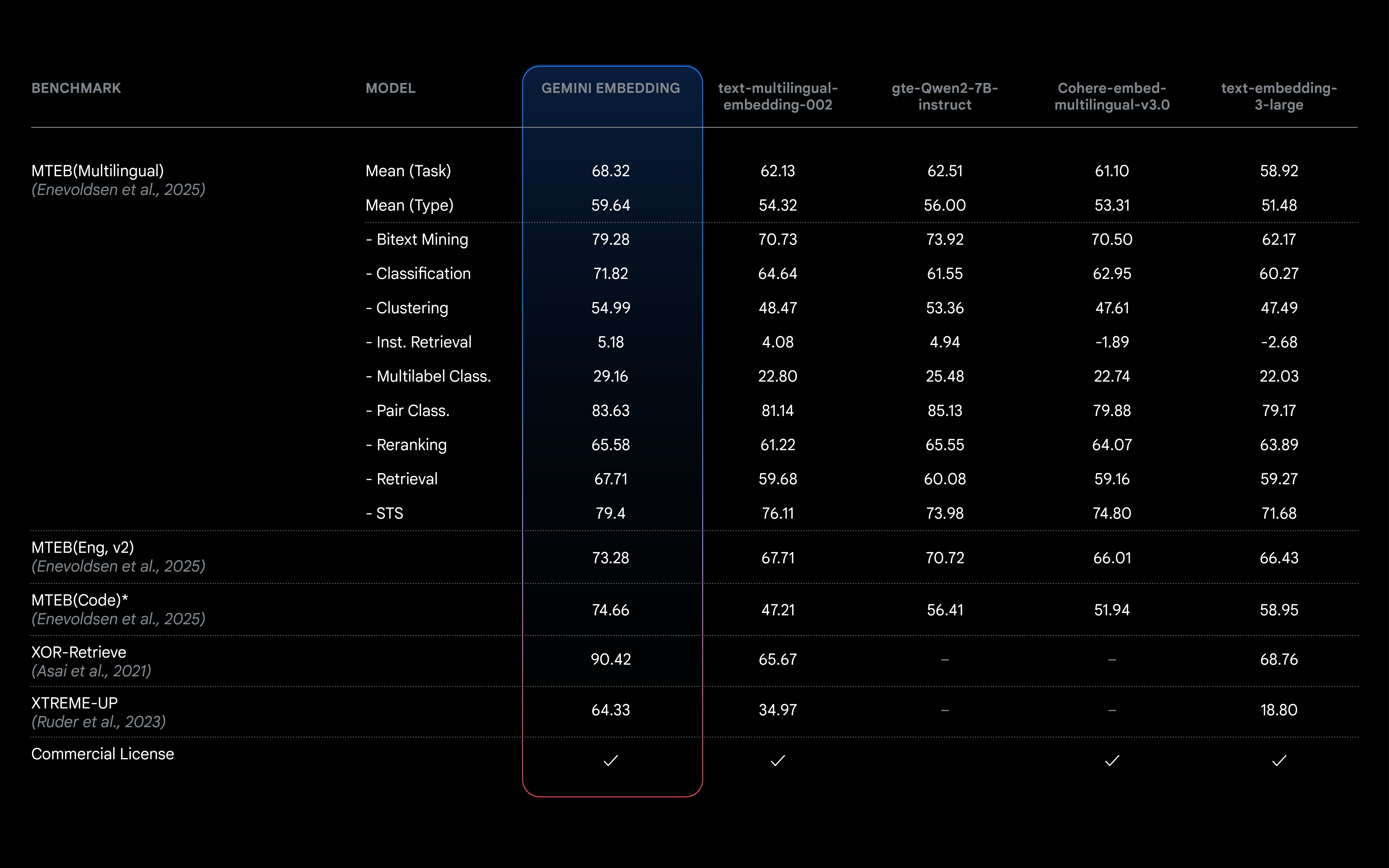
Gemini Embedding is a state-of-the-art text embedding model developed by Google, designed to transform text into high-dimensional numerical vectors that capture semantic and contextual information. Trained on the Gemini model, it excels in language understanding, supports over 100 languages, and ranks first in the Multilingual Text Embedding Benchmark (MTEB). The model is versatile, supporting tasks like efficient retrieval, text classification, similarity detection, and more. It supports input tokens up to 8K in length and outputs 3K-dimensional vectors, with flexible dimension adjustment using Matryoshka Representation Learning (MRL) technology. Integrated into the Gemini API, it is ideal for developers, data scientists, and enterprise teams.

START (Self-Taught Reasoner with Tools) is a novel reasoning model developed by Alibaba Group and the University of Science and Technology of China. It enhances the reasoning capabilities of large language models (LLMs) by integrating external tools such as Python code executors. START employs the "Hint-infer" technique to insert prompts during the reasoning process, encouraging the model to use external tools. It also utilizes the "Hint-RFT" framework for self-learning and fine-tuning. START introduces tool invocation on top of long-chain reasoning (Long CoT), significantly improving accuracy and efficiency in complex mathematical problems, scientific questions, and programming challenges. It has outperformed existing models in multiple benchmarks and is the first open-source model to combine long-chain reasoning with tool integration.
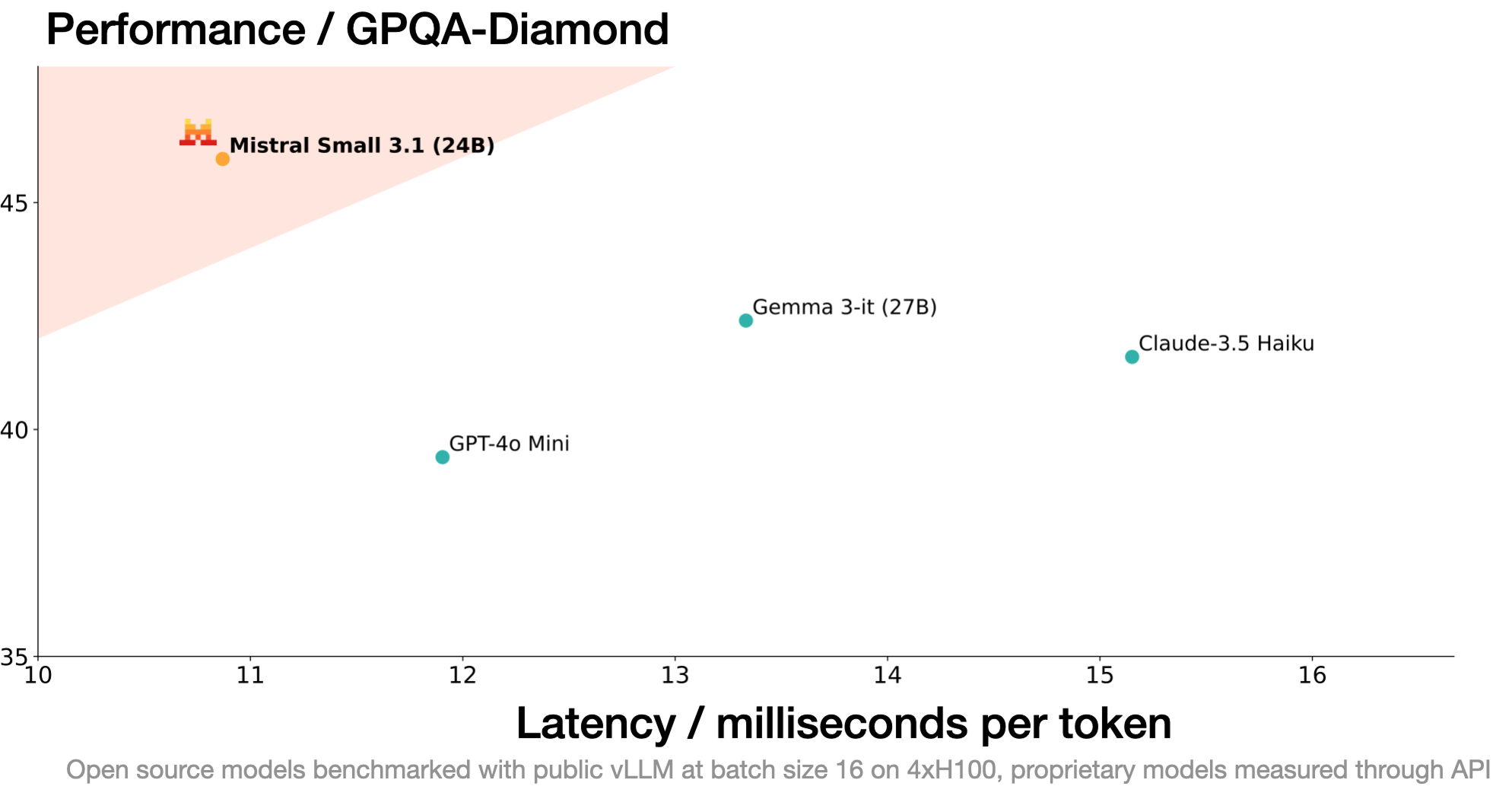
Mistral Small 3.1 is an open-source multimodal AI model developed by Mistral AI, featuring 24 billion parameters and released under the Apache 2.0 license. It excels in both text and image processing tasks, supporting a context window of up to 128k tokens and achieving inference speeds of up to 150 tokens per second. The model is optimized for efficiency, capable of running on a single RTX 4090 or a 32GB RAM Mac, making it suitable for local deployment. It supports up to 25 languages and performs well in benchmarks like MMLU and MMLU Pro, offering strong multimodal understanding capabilities.

SmolDocling is a compact, multimodal document processing model designed for efficient conversion of document images into structured text. It supports a variety of elements including text, formulas, charts, and tables, making it suitable for academic papers, technical reports, and other document types. With only 256M parameters, it ensures fast inference speeds, processing each page in just 0.35 seconds on an A100 GPU. The model is fully compatible with Docling and supports multiple export formats.
Moshi is an end-to-end real-time audio multimodal AI model developed by the French AI research lab Kyutai. It can listen, speak, and simulate 70 different emotions and styles for communication. As an open-source model comparable to GPT-4o, Moshi can run on regular laptops, features low latency, supports local device usage, and protects user privacy. The development and training process of Moshi is simple and efficient, completed by an 8-person team in 6 months. The code, weights, and technical papers of Moshi will soon be open-sourced for free use and further research by global users.









