All Models Complete list of AI models and foundation models, sorted by newest first

Recraft V3 is an advanced AI text-to-image generation model developed by Recraft, designed to produce high-quality images with precise design control. It has achieved the top position on Hugging Face's text-to-image model leaderboard with an ELO score of 1172. The model allows users to customize brand styles, control text and element positioning, and supports long text generation. Recraft V3 is accessible via a user-friendly interface, mobile apps, and API, making it a versatile tool for designers and creative professionals.
AlphaFold 3, developed by Google DeepMind, is an advanced AI model designed to predict the 3D structures of various biomolecules, including proteins, nucleic acids, small molecules, ions, and modified residues. This open-source model has significantly improved the accuracy of structural predictions, making it a valuable tool in drug design, scientific research, and biomedical applications. By enabling global scientists to accelerate the development of new drugs and vaccines, AlphaFold 3 is transforming the field of structural biology.

RMBG-2.0 is an open-source image background removal model developed by BRIA AI, designed to achieve high-precision separation of foreground and background in images. Leveraging advanced AI technology, it reaches state-of-the-art (SOTA) levels of accuracy, outperforming its predecessor and even well-known paid tools like remove.bg. Trained on over 15,000 high-resolution images, RMBG-2.0 is highly accurate and applicable across various fields such as e-commerce, advertising, and game development.

DeepSeek-VL2 is an open-source series of large-scale Mixture-of-Experts (MoE) vision-language models developed by DeepSeek. It significantly improves upon its predecessor, DeepSeek-VL, and excels in tasks such as visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. The model series includes three versions: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, and DeepSeek-VL2, with 1.0B, 2.8B, and 4.5B activated parameters, respectively. DeepSeek-VL2 supports resolutions up to 1152x1152 and extreme aspect ratios of 1:9 or 9:1, making it versatile for various applications. It also features advanced capabilities like understanding scientific charts and generating Python code from images using the Plot2Code feature.
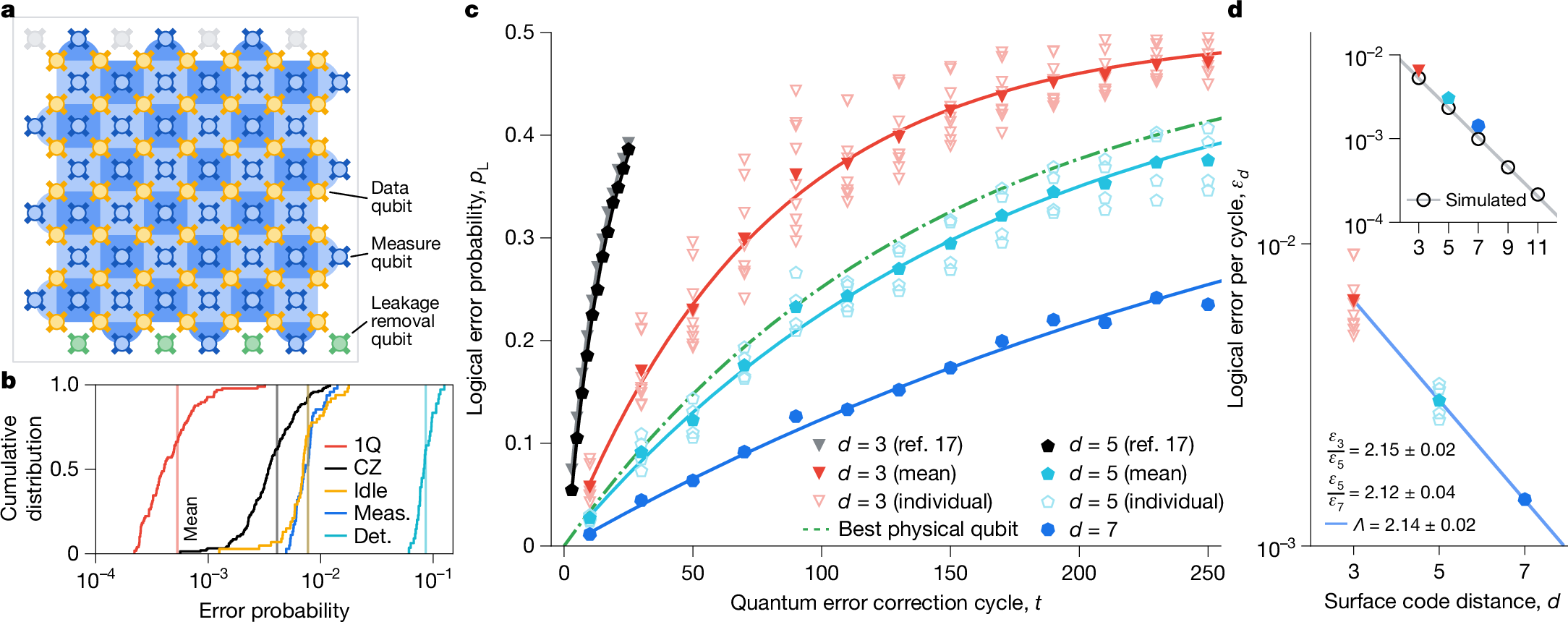
The Willow Quantum Chip, developed by Google, is a cutting-edge quantum processor featuring 105 physical qubits. It addresses a 30-year challenge in quantum error correction, significantly reducing error rates while increasing qubit count. The chip completes a standard benchmark calculation in less than five minutes, a task that would take the fastest supercomputer 10^25 years. This innovation marks a significant step toward the commercialization of quantum computing, with potential applications in medicine, energy, AI, and more.
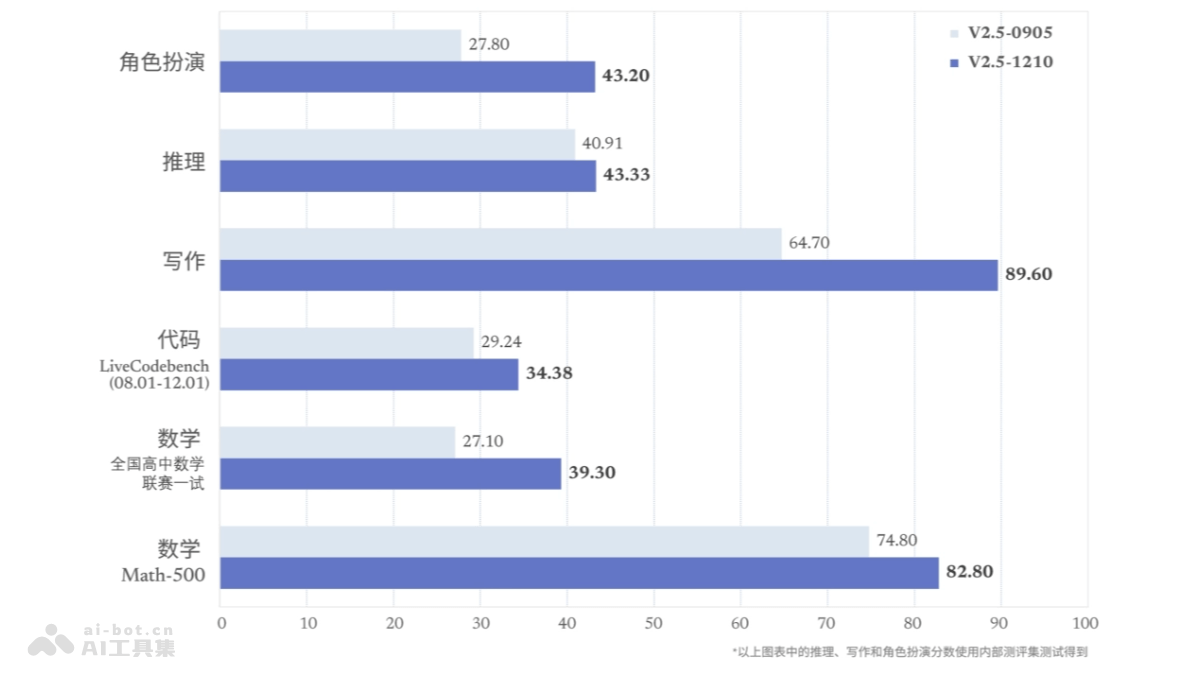
DeepSeek-V2.5-1210 is the final fine-tuned model of DeepSeek V2.5, based on Post-Training iteration, which improves performance in math, programming, writing, and role-playing. It supports online search functionality, providing comprehensive, accurate, and personalized answers on the web, automatically extracting keywords for parallel searches, and delivering diverse results quickly. The model weights are open-sourced on Huggingface for developers and researchers.

LAM, or "Large Action Model," is an AI model developed by Microsoft designed to autonomously operate Windows programs. Unlike traditional language models, LAM converts user requests into specific actions, such as launching applications or controlling devices. It is optimized for Microsoft Office and other Windows applications, achieving a 71% task completion success rate in Word, outperforming GPT-4. LAM excels in understanding user intent, generating actions, and dynamically adapting to complex tasks.
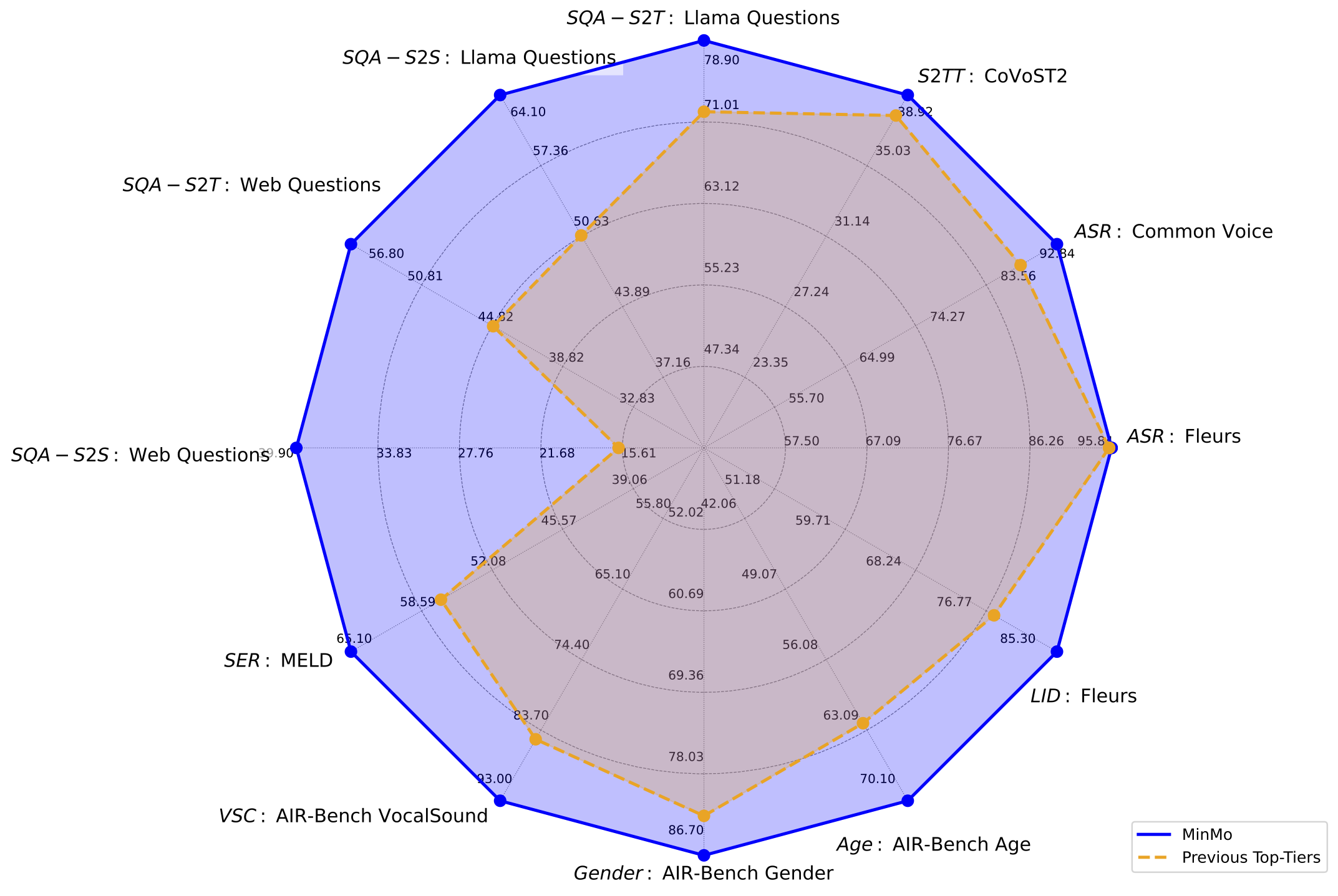
MinMo is a multimodal large model developed by the FunAudioLLM team at Alibaba Tongyi Lab, designed to achieve seamless voice interaction. With approximately 8 billion parameters, MinMo is trained on 1.4 million hours of diverse voice data and supports controlling emotion, dialect, and speaking style in generated audio. It enables full-duplex voice interaction with low latency, making multi-turn conversations smoother and more natural.

Goku is a cutting-edge video generation model developed by the University of Hong Kong and ByteDance. Built on a rectified flow Transformer framework, it excels in generating high-quality videos and images from text or image inputs. Goku supports multiple modes, including text-to-video, image-to-video, and text-to-image, making it versatile for various creative and commercial applications. It is particularly effective in reducing advertising video production costs by up to 100 times compared to traditional methods. Goku is trained on a massive dataset of 36 million videos and 160 million images, ensuring high-quality outputs. Advanced parallel strategies and fault-tolerant mechanisms further enhance its efficiency and stability.
YAYI-Ultra is the flagship enterprise-level large language model developed by Wenge Research. It excels in multi-domain expertise and multimodal content generation, supporting fields such as mathematics, coding, finance, public opinion, traditional Chinese medicine, and security. The model supports inputs of up to 128k tokens, longer context windows, and multimodal capabilities aligned with over 10 million text-image data pairs. It also features multi-turn dialogue role-playing, content security risk control, and the invocation of 10+ intelligent plugins.









