All Frameworks Complete list of AI frameworks, sorted by newest first

MimicMotion, developed by Tencent, is an advanced AI framework for generating high-quality human motion videos. It utilizes confidence-aware pose guidance to ensure smooth transitions and detailed hand movements. The framework employs region loss amplification and hand region enhancement to reduce image distortion and improve visual quality. MimicMotion can generate long videos with high temporal coherence using a progressive latent fusion strategy, making it ideal for applications in dance, sports, and daily activities.
PuLID is an open-source framework developed by ByteDance for personalized text-to-image generation. It leverages contrastive alignment and fast sampling methods to achieve efficient ID customization without requiring model tuning. This technology allows users to create realistic face-swapping effects while maintaining high ID fidelity and minimizing interference with the original image's style and background. PuLID supports personalized editing through simple text prompts, making it scalable for applications in art creation, virtual avatar customization, and film production.

Agent Q is a self-supervised agent reasoning and search framework developed by MultiOn in collaboration with Stanford University. It integrates techniques such as guided Monte Carlo Tree Search (MCTS), AI self-criticism, and Direct Preference Optimization (DPO) to enable AI models to self-improve through iterative fine-tuning and reinforcement learning based on human feedback. Agent Q has demonstrated exceptional performance in web navigation and multi-step task execution, significantly improving success rates in real-world tasks like OpenTable reservations.

MovieDreamer is an AI video generation framework developed by Zhejiang University in collaboration with Alibaba, specifically designed for long videos. It combines autoregressive models and diffusion rendering techniques to generate long videos with complex plots and high visual quality. Through multimodal script enhancements, it improves scene descriptions, maintains character and scene consistency, significantly extends the duration of generated content, and advances the development of automated long video production technology.
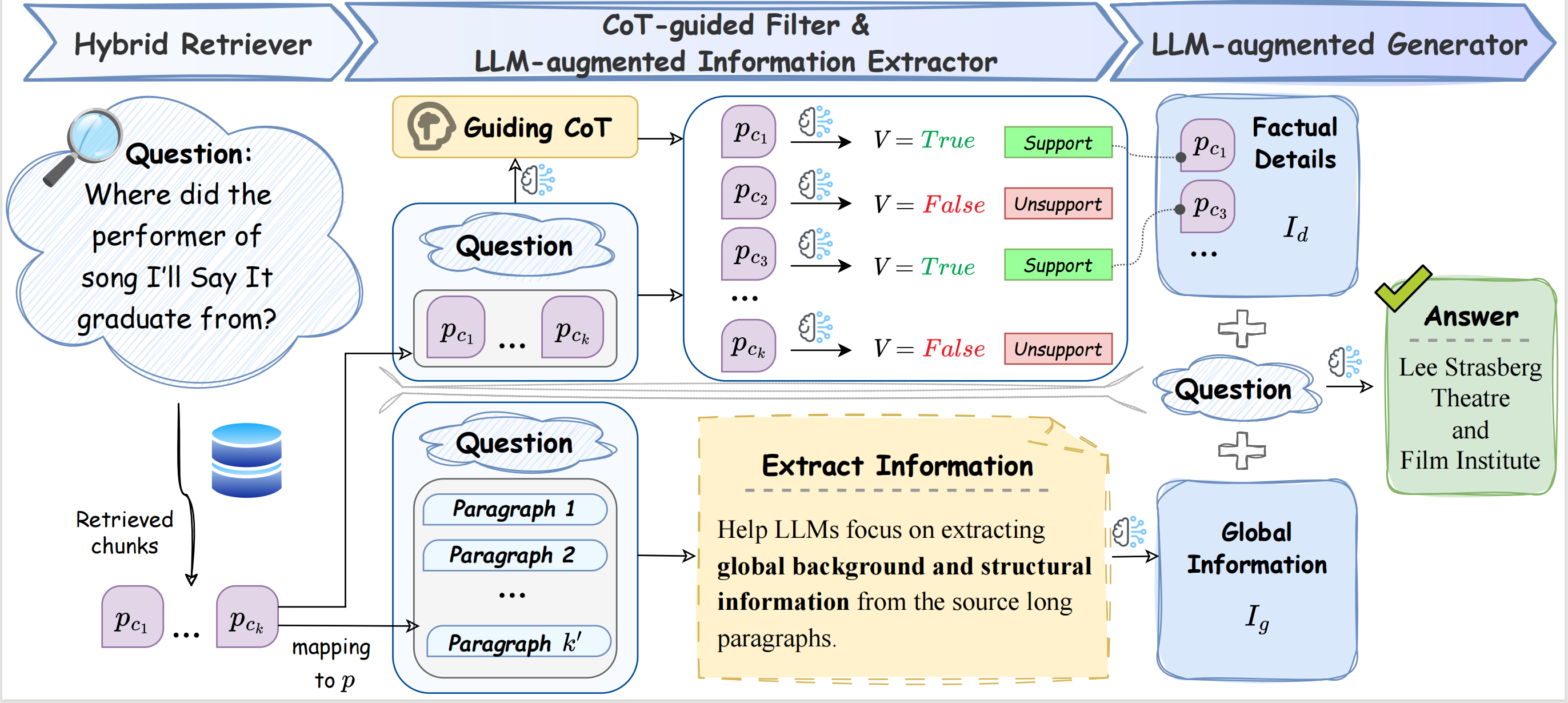
LongRAG is a robust retrieval-augmented generation (RAG) framework developed by Tsinghua University, the Chinese Academy of Sciences (CAS), and ZhiPu. It is specifically designed for long-context question answering (LCQA), addressing challenges in global context understanding and factual detail recognition. The framework includes a hybrid retriever, an LLM-enhanced information extractor, a CoT-guided filter, and an LLM-enhanced generator. LongRAG outperforms baseline models on multiple datasets and offers an automated fine-tuning data construction pipeline to enhance domain adaptability and instruction-following capabilities.
ClearerVoice-Studio is an open-source voice processing framework developed by Alibaba DAMO Academy's Tongyi Lab. It integrates functions such as voice enhancement, separation, and speaker extraction from audio and video. The framework is based on complex-domain deep learning algorithms, effectively eliminating background noise while preserving voice clarity and minimizing distortion. It provides advanced pre-trained models and training scripts, supporting researchers and developers in voice processing tasks and promoting innovative applications of voice processing technology.
DeepGEMM is an open-source library by DeepSeek specifically designed for FP8 (8-bit floating point) matrix multiplication (GEMM). It supports both regular and Mixture of Experts (MoE) grouped GEMM operations, utilizing Just-In-Time (JIT) compilation for dynamic optimization at runtime. Optimized for NVIDIA Hopper Tensor Cores, DeepGEMM leverages fine-grained scaling and CUDA core dual-level accumulation to address FP8 precision issues while enhancing data transfer efficiency with Hopper's Tensor Memory Accelerator (TMA) feature. Its lightweight design, with core code of only about 300 lines, achieves or surpasses expert-level optimization libraries across various matrix shapes.

Diffutoon is an AI framework developed by researchers from Alibaba and East China Normal University (ECNU) that transforms realistic videos into cartoon anime styles. It leverages diffusion model-based editable cartoon coloring technology to achieve high-resolution and long-duration video rendering. The framework also includes content editing capabilities, allowing users to adjust video details based on text prompts, ensuring high visual quality and consistency in the final output.
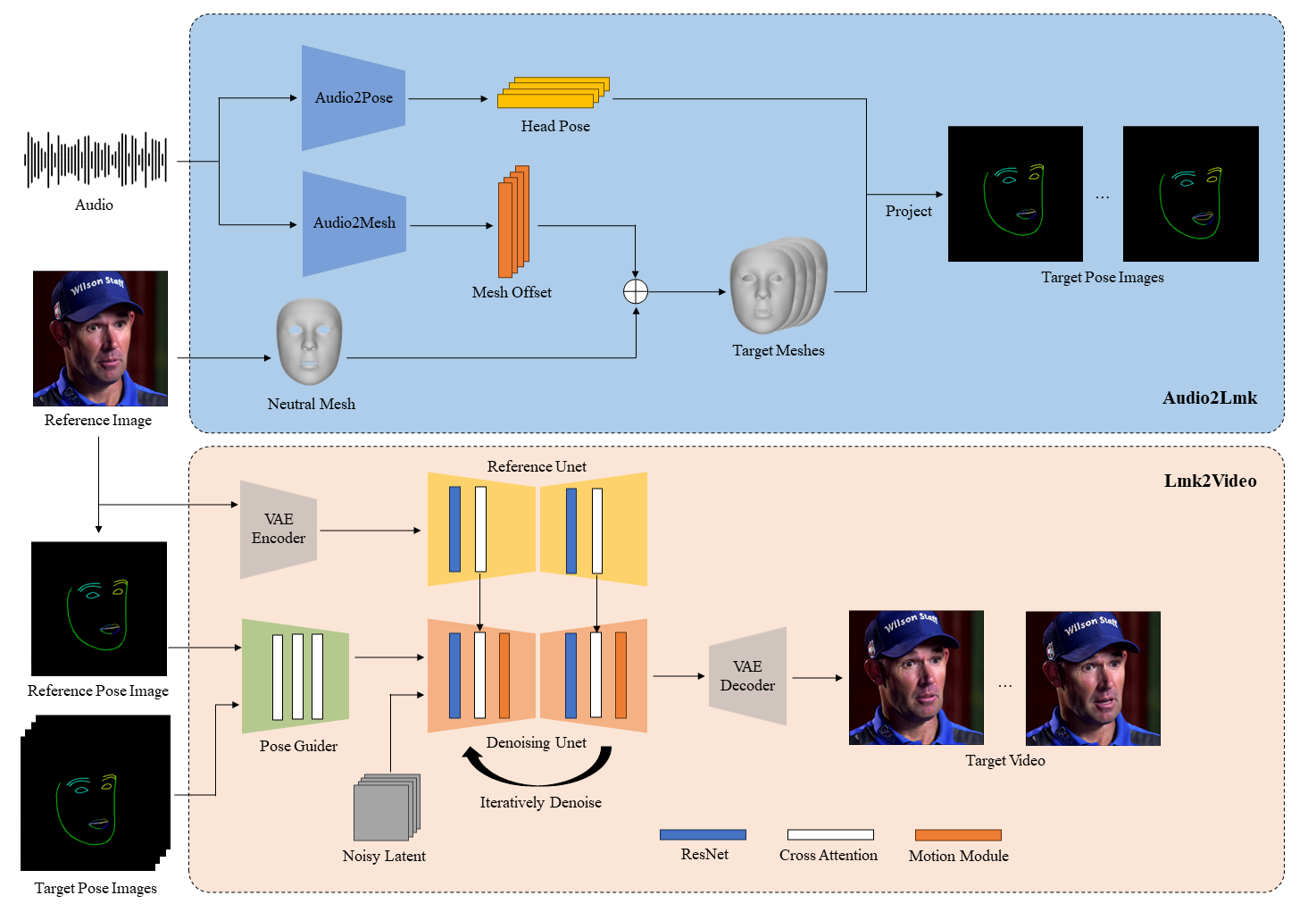
AniPortrait is an open-source framework developed by Tencent that transforms audio and a portrait image into high-quality, lip-synced animated videos. It operates in two stages: extracting 3D facial features from audio and converting them into 2D facial landmarks, then using a diffusion model and motion module to generate realistic animations. The framework excels in producing natural, diverse animations with precise lip-syncing and facial expressions, offering flexibility for editing and customization.
3FS (Fire-Flyer File System) is a high-performance distributed file system developed by DeepSeek, specifically optimized for AI training and inference workloads. It leverages modern SSD and RDMA network technologies to aggregate the throughput of thousands of SSDs and the network bandwidth of hundreds of storage nodes, delivering up to 6.6 TiB/s read throughput. 3FS ensures strong consistency, provides a universal file interface, and eliminates the need for learning new storage APIs. It is ideal for large-scale data processing, inference optimization, and high-throughput parallel checkpointing.
Helping everyone find the best AI for their work and daily life through deep analysis and honest comparisons.
Categories
Stay Updated
Get notified about new AI tools, models, and insights.









