All Models Complete list of AI models and foundation models, sorted by newest first
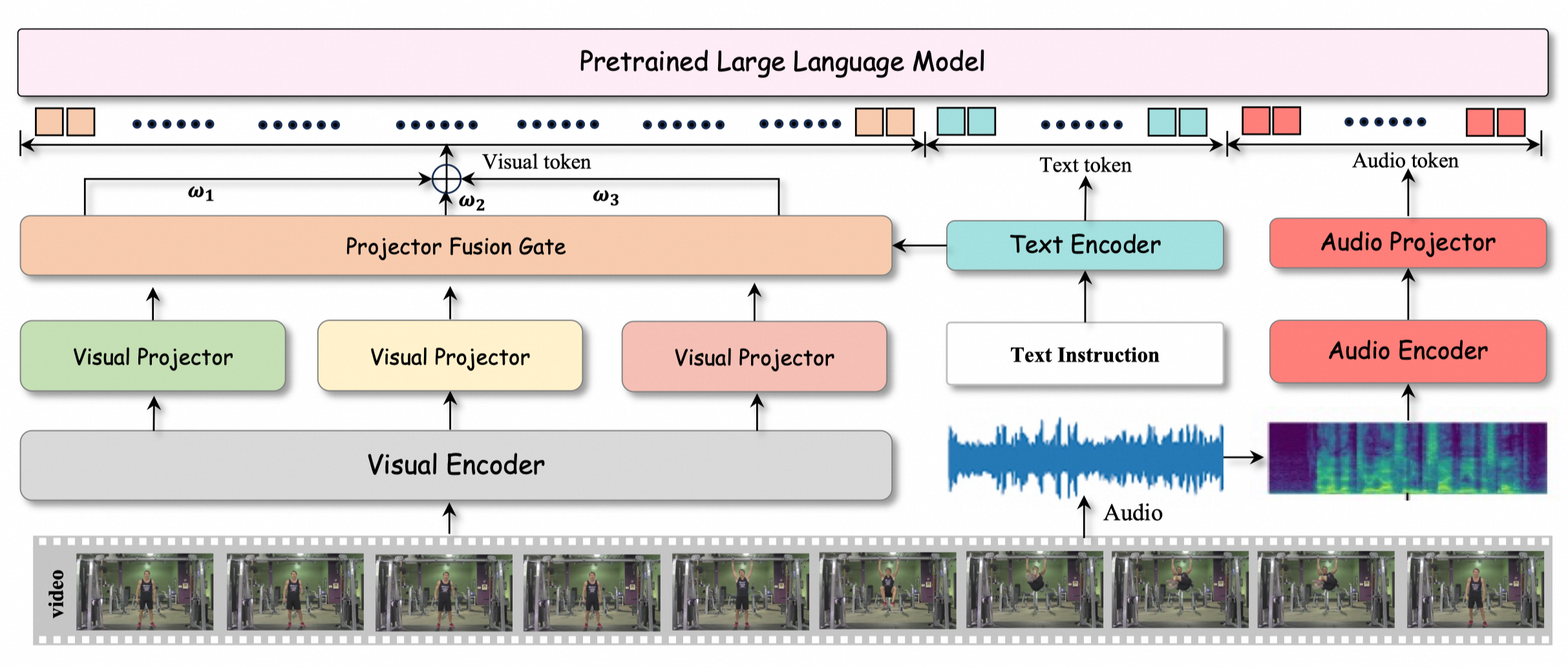
HumanOmni is a multimodal large model designed for human-centric scenarios, integrating visual and auditory modalities. It processes video, audio, or a combination of both to understand human behavior, emotions, and interactions. Pre-trained on over 2.4 million video clips and 14 million instructions, HumanOmni employs a dynamic weight adjustment mechanism to flexibly fuse visual and auditory information. It excels in tasks like emotion recognition, facial description, and speech recognition, making it suitable for applications such as movie analysis, close-up video interpretation, and real-time video understanding.

Soundwave is an open-source speech understanding model developed by The Chinese University of Hong Kong (Shenzhen). It specializes in the intelligent alignment and comprehension of speech and text, leveraging innovative alignment and compression adapter technologies to bridge the representation gap between speech and text. This enables efficient speech feature compression and enhanced performance in various speech-related tasks.

Parler-TTS is an open-source text-to-speech (TTS) model developed by Hugging Face. It generates high-quality, natural-sounding speech by mimicking specific speaker styles (gender, pitch, speaking style, etc.) based on input prompts. The model is fully open-source, including datasets, preprocessing, training code, and weights, promoting innovation in high-quality, controllable TTS models. Its architecture is based on MusicGen, integrating text encoders, decoders, and audio codecs to optimize voice generation through text descriptions and embedding layers.

Qwen2-Audio is an open-source AI speech model developed by Alibaba's Tongyi Qianwen team. It supports direct voice input and multilingual text output, enabling features like voice chat, audio analysis, and support for over 8 languages. The model excels in performance on benchmark datasets and is integrated into Hugging Face's transformers library, making it accessible for developers. It also supports fine-tuning for specific applications.

MiniCPM 3.0 is a high-performance edge AI model developed by FaceWall Intelligence, featuring 4B parameters. Despite its smaller size, it surpasses GPT-3.5 in performance. The model utilizes LLMxMapReduce technology to support infinite-length text processing, effectively expanding its contextual understanding capabilities. In Function Calling, MiniCPM 3.0 performs close to GPT-4o, demonstrating excellent edge-side execution capabilities. The model also includes the RAG trio (retrieval, re-ranking, and generation models), significantly improving Chinese retrieval and content generation quality. MiniCPM 3.0 is fully open-source, with the quantized model occupying only 2GB of memory, making it ideal for edge-side deployment while ensuring data security and privacy.

Marco is a large-scale commercial translation model developed by Alibaba International, supporting 15 global languages including Chinese, English, Japanese, Korean, Spanish, and French. It excels in context-based translation, outperforming competitors like Google Translate, DeepL, and GPT-4 in BLEU evaluation metrics. Marco uses advanced multilingual data filtering and parameter expansion techniques to ensure high-quality translations and reduce service costs. It is optimized for cross-border e-commerce, offering precise translations for product titles, descriptions, and customer interactions. Marco is available on Alibaba's AI platform, Aidge, and is designed for large-scale commercial use.

SeedVR is a diffusion transformer model developed by Nanyang Technological University and ByteDance, capable of high-quality universal video restoration. It introduces a shifted window attention mechanism, using large (64x64) windows and variable-sized windows at boundaries, effectively processing videos of any length and resolution. SeedVR combines a causal video variational autoencoder (CVVAE) to reduce computational costs while maintaining high reconstruction quality. Through large-scale joint training of images and videos and a multi-stage progressive training strategy, SeedVR excels in various video restoration benchmarks, particularly in perceptual quality and speed.
Mini-Omni is an open-source, end-to-end voice dialogue model that supports real-time voice input and output, allowing for seamless voice-to-voice dialogue without the need for additional Automatic Speech Recognition (ASR) or Text-to-Speech (TTS) systems. It employs a text-guided voice generation method, enhancing performance through batch parallel strategies while maintaining the original model's language capabilities. Mini-Omni is designed for applications requiring real-time, natural voice interactions, such as smart assistants, customer service, and smart home control.
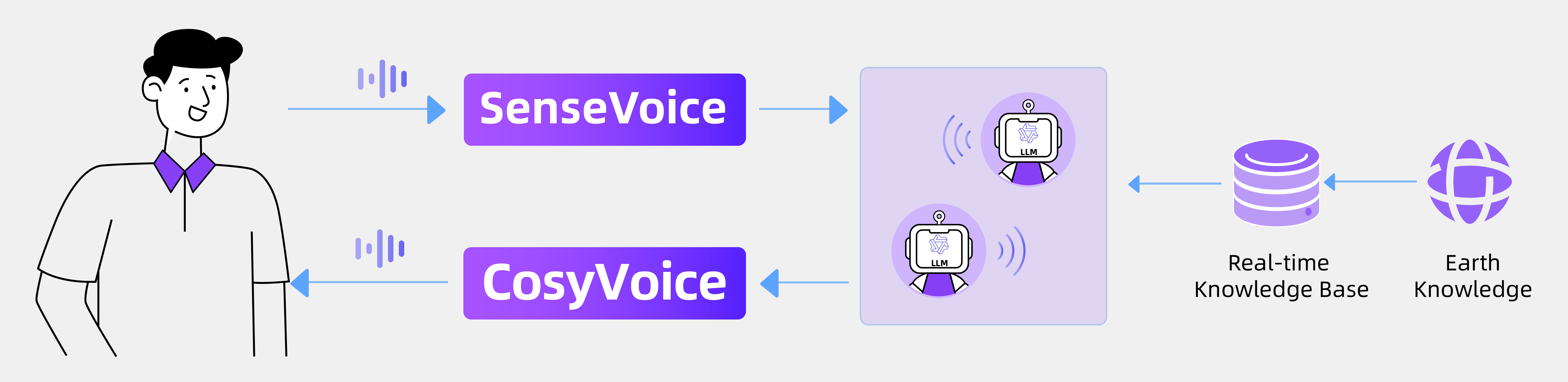
FunAudioLLM is an open-source speech large model project developed by Alibaba Tongyi Lab, consisting of two models: SenseVoice and CosyVoice. SenseVoice excels in multilingual speech recognition and emotion detection, supporting over 50 languages, with particularly strong performance in Chinese and Cantonese. CosyVoice focuses on natural speech generation, capable of controlling tone and emotion, and supports Chinese, English, Japanese, Cantonese, and Korean. FunAudioLLM is suitable for scenarios such as multilingual translation and emotional voice dialogue. The related models and code have been open-sourced on the Modelscope and Huggingface platforms.
Phi-3.5 is a cutting-edge AI model series developed by Microsoft, comprising three specialized models: Phi-3.5-mini-instruct, Phi-3.5-MoE-instruct, and Phi-3.5-vision-instruct. These models are optimized for lightweight inference, expert mixture systems, and multimodal tasks, respectively. The series supports a 128k context length, excels in multilingual processing, and enhances multi-turn dialogue capabilities. It is licensed under the MIT open-source license and has demonstrated superior performance in benchmark tests against models like GPT4o, Llama 3.1, and Gemini Flash.









